1.2.4 결정 트리, 랜덤 포레스트, 그레이디언트 부스팅 머신
결정 트리(decision tree)는 플로차트(flowchart) 같은 구조를 가지며 입력 데이터 포인트를 분류하거나 주어진 입력에 대해 출력 값을 예측합니다(그림 1-11). 결정 트리는 시각화하고 이해하기 쉽습니다. 데이터에서 학습되는 결정 트리는 2000년대부터 연구자들에게 크게 관심을 받기 시작했고 2010년까지는 커널 방법보다 선호되곤 했습니다.
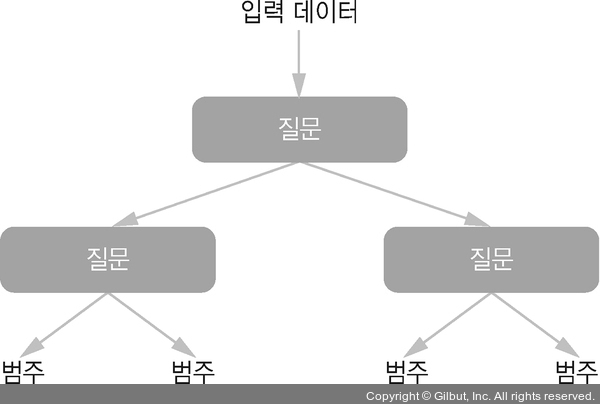
▲ 그림 1-11 결정 트리: 학습된 파라미터는 데이터에 관한 질문으로, 예를 들어 “데이터에 있는 두 번째 특성이 3.5보다 큰가?” 같은 질문이 될 수 있다
특히 랜덤 포레스트(Random Forest) 알고리즘은 결정 트리 학습에 기초한 것으로 안정적이고 실전에서 유용합니다. 서로 다른 결정 트리를 많이 만들고 그 출력을 앙상블하는 방법을 사용합니다. 랜덤 포레스트는 다양한 문제에 적용할 수 있습니다. 얕은 학습에 해당하는 어떤 작업에서도 거의 항상 두 번째로 가장 좋은 알고리즘입니다. 잘 알려진 머신 러닝 경연 웹 사이트인 캐글(Kaggle)(https://www.kaggle.com)이 2010년에 시작되었을 때부터 랜덤 포레스트가 가장 선호하는 알고리즘이 되었습니다. 2014년에 그레이디언트 부스팅 머신(gradient boosting machine)이 그 뒤를 이어받았습니다. 랜덤 포레스트와 아주 비슷하게 그레이디언트 부스팅 머신은 약한 예측 모델인 결정 트리를 앙상블하는 것을 기반으로 하는 머신 러닝 방법입니다. 이 알고리즘은 이전 모델에서 놓친 데이터 포인트를 보완하는 새로운 모델을 반복적으로 훈련함으로써 머신 러닝 모델을 향상하는 방법인 그레이디언트 부스팅(gradient boosting)을 사용합니다. 결정 트리에 그레이디언트 부스팅 방법을 적용하면 비슷한 성질을 가지면서도 대부분의 경우에 랜덤 포레스트의 성능을 능가하는 모델을 만듭니다. 이 알고리즘이 오늘날 지각에 관련되지 않은 데이터를 다루기 위한 알고리즘 중 최고는 아니지만 가장 뛰어난 것 중 하나입니다. 딥러닝을 제외하고 캐글 경연 대회에서 가장 많이 사용되는 방법입니다.