4. 모델의 파라미터에 대한 손실 함수의 그레이디언트를 계산합니다(이를 역방향 패스(backward pass)라고 부릅니다).
5. 그레이디언트의 반대 방향으로 파라미터를 조금 이동시킵니다. 예를 들어 W -= learning_rate * gradient처럼 하면 배치에 대한 손실이 조금 감소할 것입니다. 학습률(learning rate)(식에 있는 learning_rate)은 경사 하강법 과정의 속도를 조절하는 스칼라 값입니다.
아주 쉽네요! 방금 전에 이야기한 것이 미니 배치 확률적 경사 하강법(mini-batch stochastic gradient descent)(미니 배치 SGD)입니다. 확률적(stochastic)이란 단어는 각 배치 데이터가 무작위로 선택된다는 의미입니다(확률적이란 것은 무작위(random)하다는 것의 과학적 표현입니다). 모델의 파라미터가 하나고 훈련 샘플이 하나일 때 이 과정을 그림 2-18에 나타냈습니다.
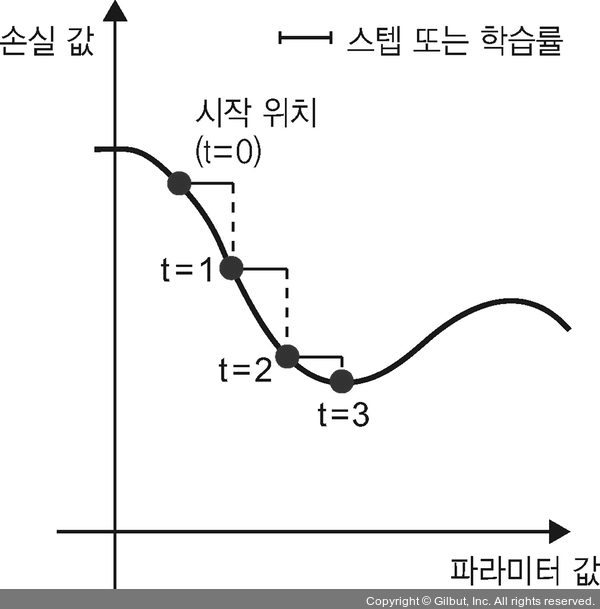
▲ 그림 2-18 SGD가 1D 손실 함수(1개의 학습 파라미터)의 값을 낮춘다