

















실제 예를 들어 머신 러닝을 활용하는 방법에 대해 살펴보겠습니다. 중환자를 전문으로 수술하는 어느 병원의 의사가 수많은 환자를 수술해 오던 중 다음과 같은 질문을 던져 보았습니다. “혹시 수술하기 전에 수술 후의 생존율을 수치로 예측할 수 있는 방법이 없을까?”
방법이 있습니다. 자신이 그동안 집도한 수술 환자의 수술 전 상태와 수술 후 생존율을 정리해 놓은 데이터를 머신 러닝 알고리즘에 넣는 것입니다. 그러면 머신 러닝은 데이터가 가진 패턴과 규칙을 분석해서 저장해 둡니다. 이후 새로운 환자가 오면 저장된 분석 결과와 비교해 생존 가능성을 예측하게 되는 것입니다. 이것이 바로 머신 러닝이 하는 일입니다.
여기서 데이터가 입력되고 패턴이 분석되는 과정을 학습(training)이라고 합니다. 다시 말해 학습 과정은 깨끗한 좌표 평면에 기존 환자들을 하나씩 배치하는 과정이라고 할 수 있습니다. 예를 들어 환자들의 분포를 그래프 위에 펼쳐 놓고 이 분포도 위에 수술 성공과 실패 여부를 구분짓는 경계를 그려 넣습니다. 이를 잘 저장해 놓았다가 새로운 환자가 오면 분포도를 다시 꺼냅니다. 그리고 새 환자가 분포도의 어디쯤 위치하는지 정하고는 아까 그려 둔 경계선을 기준으로 이 환자의 수술 결과를 예측하는 것입니다. 이를 그림으로 표현하면 그림 2-2와 같습니다.
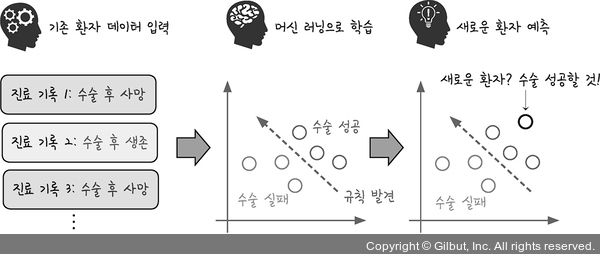
그림 2-2 | 머신 러닝의 학습 및 예측 과정
우리가 지금 배우려는 것이 바로 이러한 학습과 예측의 구체적인 과정입니다. 머신 러닝의 예측 성공률은 결국 얼마나 정확한 경계선을 긋느냐에 달려 있습니다. 따라서 더 정확한 선을 긋기 위한 여러 가지 노력이 계속되어 왔고, 그 결과 퍼셉트론(perceptron), 아달라인(adaline), 선형 회귀(linear regression) 등을 지나 오늘날 딥러닝이 탄생됩니다. 머신 러닝의 발전과 딥러닝 태동에 대해서는 7장에서 더 상세히 다루겠습니다.