4 중요한 데이터 추출하기
앞서 그림 11-3을 살펴보면 plasma 항목(공복 혈당 농도)과 BMI(체질량 지수)가 우리가 예측하고자 하는 diabetes 항목과 상관관계가 높다는 것을 알 수 있습니다. 즉, 이 항목들이 예측 모델을 만드는 데 중요한 역할을 할 것으로 기대할 수 있습니다. 이제 이 두 항목만 따로 떼어 내어 당뇨의 발병 여부와 어떤 관계가 있는지 알아보겠습니다.
먼저 plasma를 기준으로 각각 정상과 당뇨 여부가 어떻게 분포되는지 살펴봅시다.
다음과 같이 히스토그램을 그려 주는 맷플롯립 라이브러리의 hist() 함수를 이용합니다.
plt.hist(=[df.plasma[df.diabetes==0], df.plasma[df.diabetes==1]], =30, ='barstacked', =['normal','diabetes']) plt.legend()
가져오게 될 칼럼을 hist() 함수 안에 x축으로 지정합니다. 여기서는 df 안의 plasma 칼럼 중 diabetes 값이 0인 것과 1인 것을 구분해 불러오게 했습니다. bins는 x축을 몇 개의 막대로 쪼개어 보여 줄 것인지 정하는 변수입니다. barstacked 옵션은 여러 데이터가 쌓여 있는 형태의 막대바를 생성하는 옵션입니다. 불러온 데이터의 이름을 각각 normal(정상)과 diabetes(당뇨)로 정했습니다. 이를 실행시키면 그림 11-4와 같은 그래프가 형성됩니다.
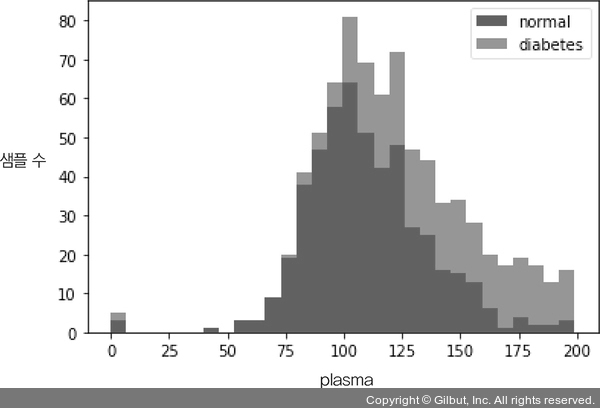
그림 11-4 | plasma를 기준으로 정상과 당뇨 여부 표시