3 학습셋과 테스트셋
그렇다면 과적합을 방지하려면 어떻게 해야 할까요?
먼저 학습을 하는 데이터셋과 이를 테스트할 데이터셋을 완전히 구분한 후 학습과 동시에 테스트를 병행하며 진행하는 것이 한 방법입니다.
예를 들어 데이터셋이 총 100개의 샘플로 이루어져 있다면 다음과 같이 두 개의 셋으로 나눕니다.

그림 13-2 | 학습셋과 테스트셋의 구분
신경망을 만들어 70개의 샘플로 학습을 진행한 후 이 학습의 결과를 저장합니다. 이렇게 저장된 파일을 ‘모델’이라고 합니다. 모델은 다른 셋에 적용할 경우 학습 단계에서 각인되었던 그대로 다시 수행합니다. 따라서 나머지 30개의 샘플로 실험해서 정확도를 살펴보면 학습이 얼마나 잘되었는지 알 수 있는 것입니다. 딥러닝 같은 알고리즘을 충분히 조절해 가장 나은 모델이 만들어지면, 이를 실생활에 대입해 활용하는 것이 바로 머신 러닝의 개발 순서입니다.
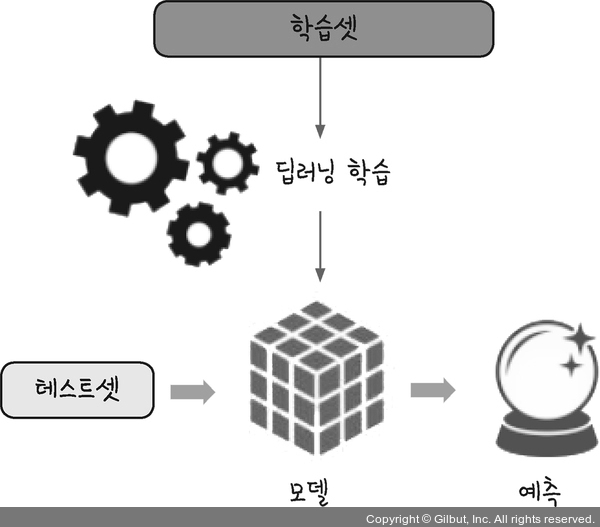
그림 13-3 | 학습셋과 테스트셋