➋ Output Shape 부분은 각 층에 몇 개의 출력이 발생하는지 나타냅니다. 쉼표(,)를 사이에 두고 괄호의 앞은 행(샘플)의 수, 뒤는 열(속성)의 수를 의미합니다. 행의 수는 batch_size에 정한 만큼 입력되므로 딥러닝 모델에서는 이를 특별히 세지 않습니다. 따라서 괄호의 앞은 None으로 표시됩니다. 여덟 개의 입력이 첫 번째 은닉층을 지나며 12개가 되고, 두 번째 은닉층을 지나며 여덟 개가 되었다가 출력층에서는 한 개의 출력을 만든다는 것을 알 수 있습니다.
➌ Param 부분은 파라미터 수, 즉 총 가중치와 바이어스 수의 합을 나타냅니다. 예를 들어 첫 번째 층의 경우 입력 값 8개가 층 안에서 12개의 노드로 분산되므로 가중치가 8×12 = 96개가 되고, 각 노드에 바이어스가 한 개씩 있으니 전체 파라미터 수는 96 + 12 = 108이 됩니다.
➍ 부분은 전체 파라미터를 합산한 값입니다. Trainable params는 학습을 진행하면서 업데이트가 된 파라미터들이고, Non-trainable params는 업데이트가 되지 않은 파라미터 수를 나타냅니다.
이 모델을 그림으로 표현하면 그림 11-6과 같습니다.
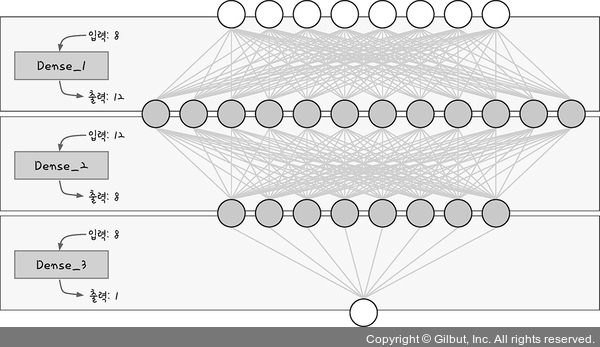
그림 11-6 | 피마 인디언 당뇨병 예측 모델의 구조