아이리스 품종 예측 데이터는 예제 파일의 data 폴더에서 찾을 수 있습니다(data/iris3.csv). 데이터의 구조는 다음과 같습니다.
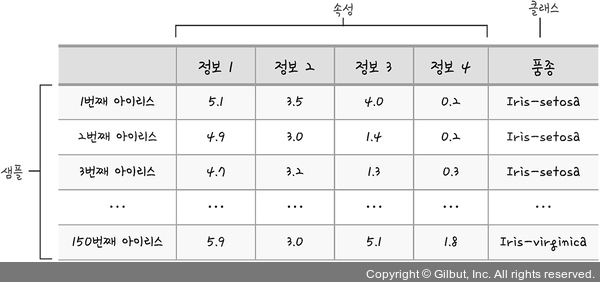
• 샘플 수: 150
• 속성 수: 4
- 정보 1: 꽃받침 길이(sepal length, 단위: cm)
- 정보 2: 꽃받침 너비(sepal width, 단위: cm)
- 정보 3: 꽃잎 길이(petal length, 단위: cm)
- 정보 4: 꽃잎 너비(petal width, 단위: cm)
• 클래스: Iris-setosa, Iris-versicolor, Iris-virginica
그림 12-2 | 아이리스 데이터의 샘플, 속성, 클래스 구분
속성을 보니 우리가 앞서 다루었던 것과 중요한 차이가 있습니다. 바로 클래스가 두 개가 아니라 세 개입니다. 즉, 참(1)과 거짓(0)으로 해결하는 것이 아니라, 여러 개 중에 어떤 것이 답인지 예측하는 문제입니다.
이렇게 여러 개의 답 중 하나를 고르는 분류 문제를 다중 분류(multi classification)라고 합니다. 다중 분류 문제는 둘 중에 하나를 고르는 이항 분류(binary classification)와는 접근 방식이 조금 다릅니다. 지금부터 아이리스 품종을 예측하는 실습을 통해 다중 분류 문제를 해결해 보겠습니다.