데이터를 이용해 성능을 향상시키려면 우선 충분한 데이터를 가져와 추가하면 됩니다. 많이 알려진 다음 그래프는 특히 딥러닝의 경우 샘플 수가 많을수록 성능이 좋아짐을 보여 줍니다.
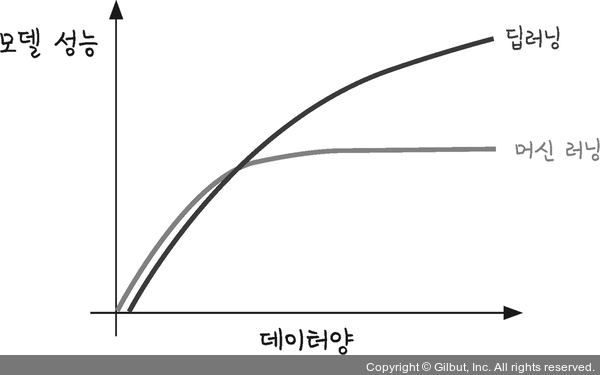
그림 13-6 | 데이터의 증가와 딥러닝, 머신 러닝 성능의 상관관계3
하지만 데이터를 추가하는 것 자체가 어렵거나 데이터 추가만으로는 성능에 한계가 있을 수 있습니다. 따라서 가지고 있는 데이터를 적절히 보완해 주는 방법을 사용합니다. 예를 들어 사진의 경우 사진 크기를 확대/축소한 것을 더해 보거나 위아래로 조금씩 움직여 넣어 보는 것입니다(20장에서 다룹니다). 테이블형 데이터의 경우 너무 크거나 낮은 이상치가 모델에 영향을 줄 수 없도록 크기를 적절히 조절할 수 있습니다. 시그모이드 함수를 사용해 전체를 0~1 사이의 값으로 변환하는 것이 좋은 예입니다. 또 교차 검증 방법을 사용해 가지고 있는 데이터를 충분히 이용하는 방법도 있습니다. 이는 잠시 후 다시 설명할 것입니다.