

















6 k‐최근접 이웃
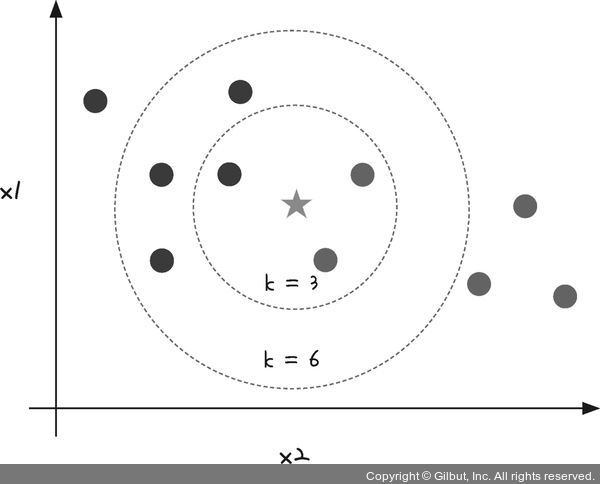
k-최근접 이웃(k-nearest neighbor)은 새로운 데이터가 입력되면 가장 가까이 있는 것을 중심으로 새로운 데이터의 종류를 정해 주는 것입니다. 예를 들어 새로운 데이터(★)가 입력되었을 때 이 데이터가 붉은 원인지 푸른 원인지를 예측한다고 합시다. 주변 데이터의 수를 k라고 하며, k = 3의 원을 보니 푸른 원이 더 많습니다. 따라서 별은 푸른 원일 수 있습니다. 그런데 범위를 조금 더 넓혀 k = 6의 결과를 보니 붉은 원이 푸른 원보다 더 많습니다. 가장 적절한 k 값은 주어진 데이터마다 다르므로 이를 결정하면서 새로운 데이터를 예측하는 방법입니다.
k-최근접 이웃을 적용해 다음과 같이 분류 모델을 만들 수 있습니다.