다음 그림은 예제 데이터셋 분포 출력 결과입니다.
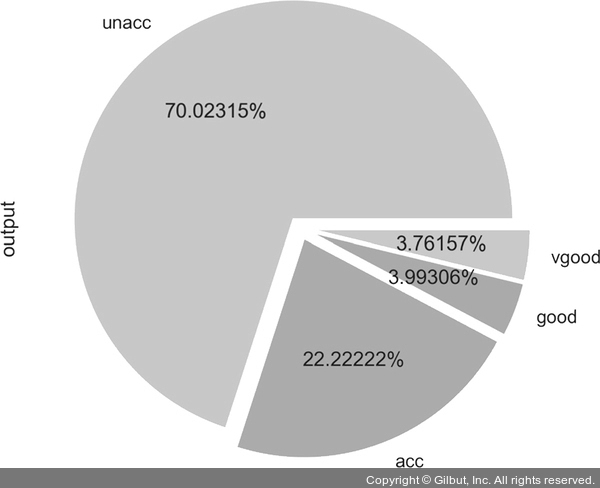
▲ 그림 2-26 예제 데이터셋 분포 결과
결과에 따르면 대부분의 자동차(70%)는 허용 불가능한 상태에 있고 20%만 허용 가능한 수준입니다. 즉, 양호한 상태의 자동차 비율이 매우 낮은 것을 볼 수 있습니다. 예제 데이터 정보를 확인했으니 본격적으로 데이터에 대한 전처리를 해 봅시다.
딥러닝은 통계 알고리즘을 기반으로 하기 때문에 단어를 숫자(텐서)로 변환해야 합니다. 가장 먼저 필요한 전처리는 데이터를 파악하는 것입니다. 주어진 데이터의 형태를 파악한 후 숫자로 변환해 주어야 하는데, 예제에서 다루는 데이터의 칼럼들은 모두 범주형 데이터(예 성별: 여자, 남자)로 구성되어 있습니다. 다음 코드로 단어를 배열로 변환하는 방법에 대해 간단히 살펴보겠습니다. 이 장의 코드는 맛보기 코드이므로 흐름만 간략히 익히고 넘어갑니다.