12.3.1 벨만 기대 방정식
가치 함수 vπ(s)는 단순히 어떤 상황에서 미래의 보상을 포함한 가치를 나타냅니다. 다음 상태로 이동하려면 어떤 정책(policy)에 따라 행동해야 하는데, 이때 정책을 고려한 다음 상태로의 이동이 벨만 기대 방정식(Bellman expectation equation)입니다.
벨만 기대 방정식으로 상태-가치 함수와 행동-가치 함수를 기댓값 E로 표현할 수 있습니다. 상태-가치 함수의 벨만 기대 방정식을 알아보기 전에 MDP의 상태-가치 함수에 대한 도출 과정을 먼저 살펴봅시다.
MDP의 상태-가치 함수에 대한 수식을 다시 써 보겠습니다.
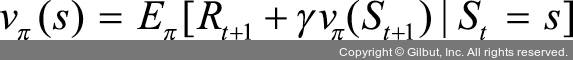
여기에서 t+2 시점부터의 보상(γRt+2 + γRt+3 + …)을 할인율(γ(Rt+2 + Rt+3 + …))로 묶어 주면, 이 묶인 수식은 t+1 시점부터 받을 보상을 의미합니다. 다시 말해 t+1 시점에서의 가치 함수로 표현할 수 있습니다. 즉, 다음과 같이 다음 상태와 현재 상태의 가치 함수 관계를 식으로 나타낼 수 있습니다.
