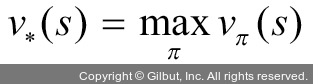12.3.2 벨만 최적 방정식
강화 학습에서 추구하고자 하는 목표는 최적의 가치 함수 값을 찾는 것이 아닌 최대의 보상을 얻는 정책을 찾는 것입니다. 즉, 최대의 보상을 얻기 위한 정책을 찾기 위해 가치 함수 값이 가장 큰 값을 찾습니다. 또한, 강화 학습에서 어떤 목표를 이루었을 때를 ‘최적(optimal)’의 상태, 즉 어떤 목적이 달성된 상태라고 합니다. 그래서 강화 학습 목표에 따라 찾은 정책을 최적화된 정책(optimal policy)이라고 하며, 이러한 최적화된 정책을 따르는 벨만 방정식을 벨만 최적 방정식(Bellman optimality equation)이라고 합니다.
최적의 가치 함수
최적의 가치 함수(optimal value function)란 최대의 보상을 갖는 가치 함수입니다. 따라서 다음과 같이 두 가지 함수의 최적화를 구할 수 있습니다.
상태-가치 함수는 어떤 상태가 더 많은 보상을 받을 수 있는지 알려 주며, 행동-가치 함수는 어떤 상태에서 어떤 행동을 취해야 더 많은 보상을 받을 수 있는지 알려 줍니다. 따라서 모든 상태에 대해 상태-가치 함수를 계산할 수 있다면, 모든 상태에 대해 최적의 행동(optimal action)을 선택할 수 있습니다.
최적의 행동을 위한 최적의 상태-가치 함수와 최적의 행동-가치 함수를 알아보겠습니다.
최적의 상태-가치 함수(optimal state-value function)
최적의 상태-가치 함수(v*(s))는 주어진 모든 정책에 대한 상태-가치 함수의 최댓값이며, 수식은 다음과 같습니다.