10.1.3 예측 기반 임베딩
예측 기반 임베딩은 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식입니다. 대표적으로 워드투벡터가 있습니다.
워드투벡터
워드투벡터(Word2Vec)는 신경망 알고리즘으로, 주어진 텍스트에서 텍스트의 각 단어마다 하나씩 일련의 벡터를 출력합니다.
워드투벡터의 출력 벡터가 2차원 그래프에 표시될 때, 의미론적으로 유사한 단어의 벡터는 서로 가깝게 표현됩니다. 이때 ‘서로 가깝다’는 의미는 코사인 유사도를 이용하여 단어 간의 거리를 측정한 결과로 나타나는 관계성을 의미합니다. 즉, 워드투벡터를 이용하면 특정 단어의 동의어를 찾을 수 있습니다.
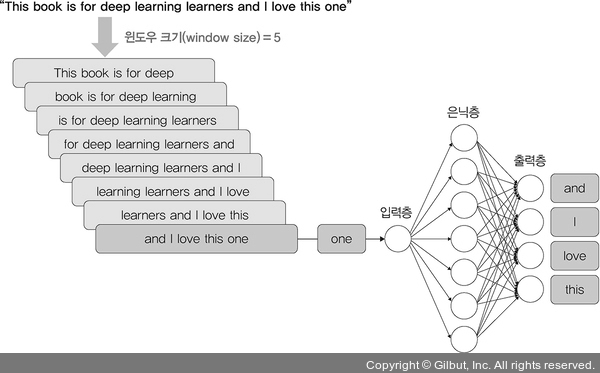
워드투벡터가 수행되는 과정은 다음 그림과 같습니다. 일정한 크기의 윈도우(window)로 분할된 텍스트를 신경망 입력으로 사용합니다. 이때 모든 분할된 텍스트는 한 쌍의 대상 단어와 컨텍스트로 네트워크에 공급됩니다. 다음 그림과 같이 대상 단어는 ‘one’이고 컨텍스트는 ‘and’, ‘I’, ‘love’, ‘this’ 단어로 구성됩니다. 또한, 네트워크의 은닉층에는 각 단어에 대한 가중치가 포함되어 있습니다.
▲ 그림 10-2 워드투벡터