8.1.1 데이터를 사용한 성능 최적화
데이터를 사용한 성능 최적화 방법은 많은 데이터를 수집하는 것입니다. 하지만 데이터 수집이 여의치 않은 상황에서는 임의로 데이터를 생성하는 방법도 고려해 볼 수 있습니다.
• 최대한 많은 데이터 수집하기: 일반적으로 딥러닝이나 머신 러닝 알고리즘은 데이터양이 많을수록 성능이 좋습니다. 따라서 가능한 많은 데이터(빅데이터)를 수집해야 합니다.
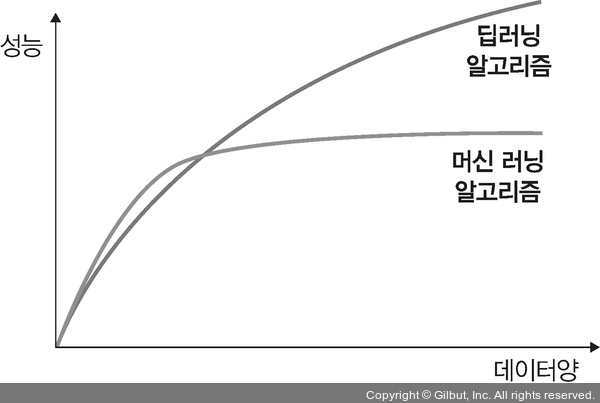
▲ 그림 8-1 데이터와 딥러닝, 머신 러닝 알고리즘의 성능 비교
• 데이터 생성하기: 많은 데이터를 수집할 수 없다면 데이터를 만들어 사용할 수 있습니다. 5장에 이미지 조작에 대한 코드가 있으니 참조하면 됩니다.
• 데이터 범위(scale) 조정하기: 활성화 함수로 시그모이드를 사용한다면 데이터셋 범위를 0~1의 값을 갖도록 하고, 하이퍼볼릭 탄젠트를 사용한다면 데이터셋 범위를 -1~1의 값을 갖도록 조정할 수 있습니다.
또한, 정규화, 규제화, 표준화도 성능 향상에 도움이 됩니다.