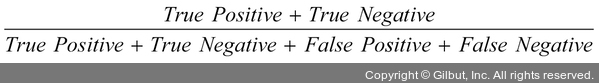신경망에서 필요한 모든 파라미터를 무작위로 선택했다는 것을 감안할 때 75%의 정확도는 나쁘지 않습니다. 파라미터(예 훈련/테스트 데이터셋 분할, 은닉층 개수 및 크기 등)를 변경하면서 더 나은 성능을 찾아보는 것도 학습에 도움이 될 것입니다.
마지막으로 딥러닝 분류 모델의 성능 평가 지표를 알아보겠습니다. 성능 평가 지표로 정확도(accuracy), 재현율(recall), 정밀도(precision), F1-스코어(F1-score)가 있습니다.
정확도를 확인하기 전에 필요한 용어들부터 살펴보겠습니다.
• True Positive: 모델(분류기)이 ‘1’이라고 예측했는데 실제 값도 ‘1’인 경우입니다.
• True Negative: 모델(분류기)이 ‘0’이라고 예측했는데 실제 값도 ‘0’인 경우입니다.
• False Positive: 모델(분류기)이 ‘1’이라고 예측했는데 실제 값은 ‘0’인 경우로, Type I 오류라고도 합니다.
• False Negative: 모델(분류기)이 ‘0’이라고 예측했는데 실제 값은 ‘1’인 경우로, Type II 오류라고도 합니다.
이러한 용어들을 사용하여 정확도, 재현율, 정밀도, F1-스코어에 대해 알아보겠습니다.
정확도
전체 예측 건수에서 정답을 맞힌 건수의 비율입니다. 이때 맞힌 정답이 긍정(positive)이든 부정(negative)이든 상관없습니다.