3.1.1 K-최근접 이웃
▼ 표 3-2 K-최근접 이웃을 사용하는 이유와 적용 환경
|
왜 사용할까? |
주어진 데이터에 대한 분류 |
|
언제 사용하면 좋을까? |
K-최근접 이웃은 직관적이며 사용하기 쉽기 때문에 초보자가 쓰면 좋습니다. 또한, 훈련 데이터를 충분히 확보할 수 있는 환경에서 사용하면 좋습니다. |
K-최근접 이웃(K-nearest neighbor)은 새로운 입력(학습에 사용하지 않은 새로운 데이터)을 받았을 때 기존 클러스터에서 모든 데이터와 인스턴스(instance)2 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘입니다. 즉, 과거 데이터를 사용하여 미리 분류 모형을 만드는 것이 아니라, 과거 데이터를 저장해 두고 필요할 때마다 비교를 수행하는 방식입니다. 따라서 K 값의 선택에 따라 새로운 데이터에 대한 분류 결과가 달라질 수 있음에 유의해야 합니다.
다음 그림과 같이 네모, 세모, 별 모양의 클러스터로 구성된 데이터셋이 있다고 합시다. 신규 데이터인 동그라미가 유입되었다면 기존 데이터들과 하나씩 거리를 계산하고 거리상으로 가장 가까운 데이터 다섯 개(K=5, 임의로 지정)를 선택하여 해당 클러스터에 할당합니다.
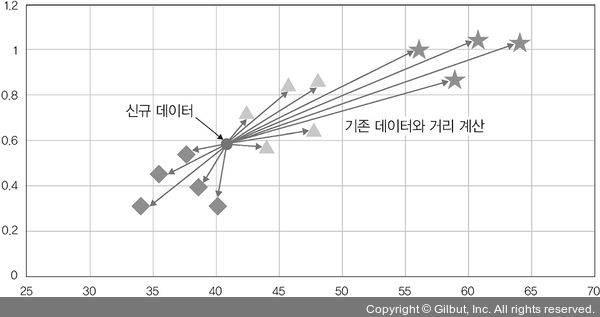
▲ 그림 3-2 K-최근접 이웃