• 속도를 조정하는 방법
아다그라드(Adagrad, Adaptive gradient)
아다그라드는 변수(가중치)의 업데이트 횟수에 따라 학습률을 조정하는 방법입니다. 아다그라드는 많이 변화하지 않는 변수들의 학습률은 크게 하고, 많이 변화하는 변수들의 학습률은 작게 합니다. 즉, 많이 변화한 변수는 최적 값에 근접했을 것이라는 가정하에 작은 크기로 이동하면서 세밀하게 값을 조정하고, 반대로 적게 변화한 변수들은 학습률을 크게 하여 빠르게 오차 값을 줄이고자 하는 방법입니다.
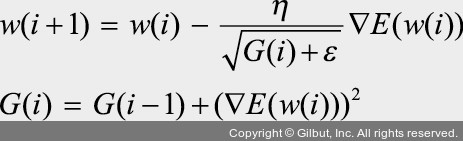
파라미터마다 다른 학습률을 주기 위해 G 함수를 추가했습니다. 이때 G 값은 이전 G 값의 누적(기울기 크기의 누적)입니다. 기울기가 크면 G 값이 커지기 때문에 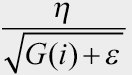 에서 학습률(η)은 작아집니다. 즉, 파라미터가 많이 학습되었으면 작은 학습률로 업데이트되고, 파라미터 학습이 덜 되었으면 개선의 여지가 많기 때문에 높은 학습률로 업데이트됩니다.
에서 학습률(η)은 작아집니다. 즉, 파라미터가 많이 학습되었으면 작은 학습률로 업데이트되고, 파라미터 학습이 덜 되었으면 개선의 여지가 많기 때문에 높은 학습률로 업데이트됩니다.
예를 들어 파이토치에서는 아다그라드를 다음과 같이 구현할 수 있습니다.
optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01) ------ 학습률 기본값은 1e-2
하지만 아다그라드는 기울기가 0에 수렴하는 문제가 있어 사용하지 않으며, 대신에 알엠에스프롭을 사용합니다.
아다델타(Adadelta, Adaptive delta)
아다델타는 아다그라드에서 G 값이 커짐에 따라 학습이 멈추는 문제를 해결하기 위해 등장한 방법입니다. 아다델타는 아다그라드의 수식에서 학습률(η)을 D 함수(가중치의 변화량(Δ) 크기를 누적한 값)로 변환했기 때문에 학습률에 대한 하이퍼파라미터가 필요하지 않습니다.
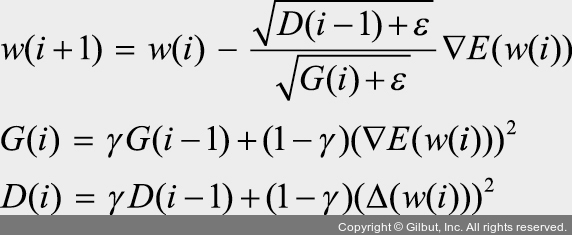
예를 들어 파이토치에서는 아다델타를 다음과 같이 구현할 수 있습니다.
optimizer = torch.optim.Adadelta(model.parameters(), lr=1.0) ------ 학습률 기본값은 1.0
알엠에스프롭(RMSProp)
알엠에스프롭은 아다그라드의 G(i) 값이 무한히 커지는 것을 방지하고자 제안된 방법입니다.
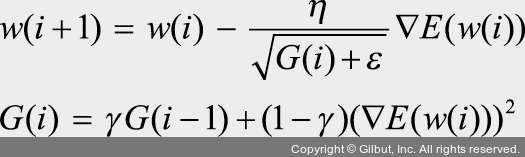
아다그라드에서 학습이 안 되는 문제를 해결하기 위해 G 함수에서 γ(감마)만 추가되었습니다. 즉, G 값이 너무 크면 학습률이 작아져 학습이 안 될 수 있으므로 사용자가 γ 값을 이용하여 학습률 크기를 비율로 조정할 수 있도록 했습니다.
예를 들어 파이토치에서는 알엠에스프롭을 다음과 같이 구현할 수 있습니다.
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01) ------ 학습률 기본값은 1e-2