다음 그림은 모델의 예측 결과를 출력한 것입니다. 참고로 데이터가 랜덤으로 섞이기 때문에 실행할 때마다 매번 결과가 다를 수 있습니다.
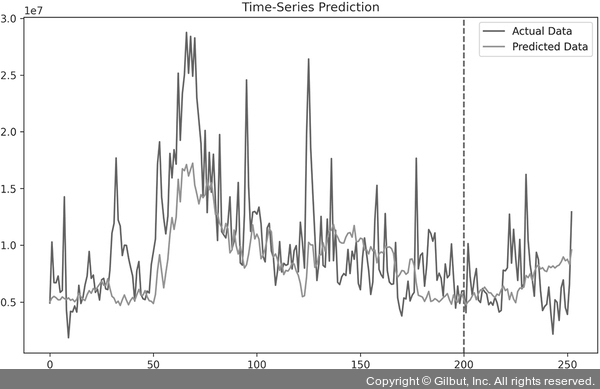
▲ 그림 7-32 양방향 LSTM 모델 예측 결과
파란색은 실제 레이블에 대한 결과이고 주황색은 모델이 예측한 결과로 이 두 개가 유사해서 예측력이 좋다고 할 수 있습니다. 따라서 LSTM과 비교했을 때 예측 결과는 좋다고 예측해 볼 수 있습니다. 하지만 역시 다른 유형의 데이터를 사용한다면 결과는 다를 수 있습니다.
지금까지 시계열 분석과 관련한 다양한 모델의 구현 방법을 알아보았습니다. 살펴본 것처럼 구현하는 것은 어렵지 않습니다. 문제는 데이터에 대한 처리입니다. 대체로 시계열 데이터들은 일반적인 숫자의 나열보다는 한글 및 영문으로 사람의 언어(자연어)로 구현된 데이터가 대부분이기 때문입니다. 따라서 시계열 구현에서 가장 중요한 것은 데이터에 대한 전처리이며, 이 부분은 ‘10장 자연어 처리를 위한 임베딩’에서 자세히 다룹니다.