다음은 StandardScaler()를 구현하는 예시 코드입니다.
from sklearn.preprocessing import StandardScaler standardScaler = StandardScaler() ------ StandardScaler 객체 생성 standardScaler.fit(train_data) train_data_standardScaled = standardScaler.transform(train_data)
정규화 방법은 예제에서 구현한 MinMaxScaler(), StandardScaler() 외에도 두 가지가 더 있습니다.
• RobustScaler(): 평균과 분산 대신 중간 값(median)과 사분위수 범위(InterQuartile Range, IQR)를 사용합니다. StandardScaler()와 비교하면 그림 9-18과 같이 정규화 이후 동일한 값이 더 넓게 분포되어 있는 것을 확인할 수 있습니다.
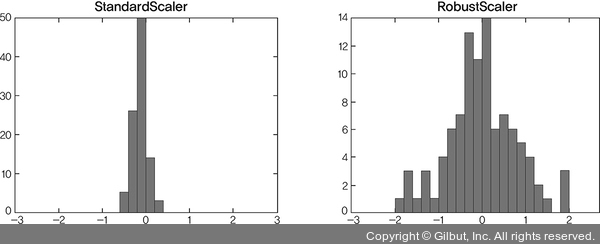
▲ 그림 9-18 StandardScaler와 RobustScaler 비교
Note ≡ | 사분위수 범위(IQR)
사분위수란 전체 관측 값을 오름차순으로 정렬한 후 전체를 사등분하는 값을 나타냅니다. 따라서 다음과 같이 표현할 수 있습니다.
• 제1사분위수 = Q1 = 제25백분위수
• 제2사분위수 = Q2 = 제50백분위수
• 제3사분위수 = Q3 = 제75백분위수
이때 제3사분위수와 제1사분위수 사이 거리를 데이터가 흩어진 정도의 척도로 사용할 수 있는데, 이 수치를 사분위수 범위(IQR)라고 합니다. 따라서 사분위수 범위는 다음과 같이 표현할 수 있습니다.
사분위수 범위: IQR = 제3사분위수 - 제1사분위수 = Q3 - Q1