TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)는 정보 검색론(Information Retrieval, IR)에서 가중치를 구할 때 사용되는 알고리즘입니다.
TF(Term Frequency)(단어 빈도)는 문서 내에서 특정 단어가 출현한 빈도를 의미합니다. 예를 들어 TF에 딥러닝과 신문기사라는 단어가 포함되어 있다고 가정합니다. 이것은 ‘신문기사’에서 ‘딥러닝’이라는 단어가 몇 번 등장했는지 의미합니다. 즉, ‘신문기사’에서 ‘딥러닝’이라는 단어가 많이 등장한다면 이 기사는 딥러닝과 관련이 높다고 할 수 있으며, 다음 수식을 사용합니다. 이때 tft,d는 특정 문서 d에서 특정 단어 t의 등장 횟수를 의미합니다.
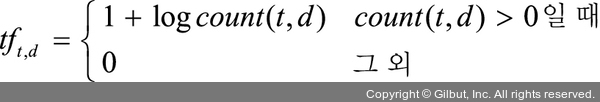
혹은

IDF(Inverse Document Frequency)(역문서 빈도)를 이해하려면 DF(Document Frequency)(문서 빈도)에 대한 개념부터 이해해야 합니다. DF는 한 단어가 전체 문서에서 얼마나 공통적으로 많이 등장하는지 나타내는 값입니다. 즉, 특정 단어가 나타난 문서 개수라고 이해하면 됩니다.
dft = 특정 단어 t가 포함된 문서 개수