skip-gram
skip-gram 방식은 CBOW 방식과 반대로 특정한 단어에서 문맥이 될 수 있는 단어를 예측합니다. 즉, skip-gram은 다음 그림과 같이 중심 단어에서 주변 단어를 예측하는 방식을 사용합니다. 예를 들어 다음 그림과 같이 중심 단어 ‘slept’를 이용하여 그 앞과 뒤의 단어들을 유추하는 것이 skip-gram입니다.
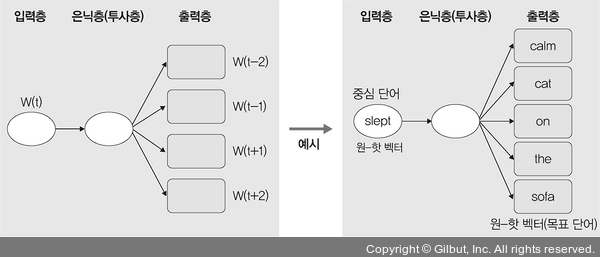
▲ 그림 10-5 skip-gram
보통 입력 단어 주변의 단어 k개를 문맥으로 보고 예측 모형을 만드는데, 이 k 값을 윈도우 크기라고 합니다.
계속해서 피터팬(peter.txt) 데이터셋을 사용한 예제입니다.
코드 10-9 데이터셋에 skip-gram 적용 후 ‘peter’와 ‘wendy’의 유사성 확인
model2 = gensim.models.Word2Vec(data, min_count=1, vector_size=100, window=5, sg=1) ------skip-gram 모델 사용
print("Cosine similarity between 'peter' " + "'wendy' - Skip Gram : ", model2.wv.similarity('peter', 'wendy')) ------ 결과 출력