12.2.3 마르코프 결정 과정
마르코프 결정 과정(Markov Decision Process, MDP)은 기존 마르코프 보상 과정에서 행동이 추가된 확률 모델입니다. MDP 목표는 정의된 문제에 대해 각 상태마다 전체적인 보상을 최대화하는 행동이 무엇인지 결정하는 것입니다. 이때 각각의 상태마다 행동 분포(행동이 선택될 확률)를 표현하는 함수를 정책(policy, π)이라고 하며, π는 주어진 상태 s에 대한 행동 분포를 표현한 것으로 수식은 다음과 같습니다.
π(a|s) = P(At = a | St = s)
MDP가 주어진 π를 따를 때 s에서 s′로 이동할 확률은 다음 수식으로 계산됩니다.
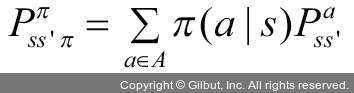
이때 s에서 얻을 수 있는 보상(R)은 다음과 같습니다.
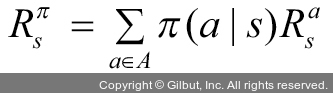
또한, MDP를 이해하기 위해서는 가치 함수도 이해해야 합니다. MDP에서 가치 함수는 에이전트가 놓인 상태 가치를 함수로 표현한 상태-가치 함수(state-value function)와 상태와 행동에 대한 가치를 함수로 표현한 행동-가치 함수(action-value function)가 있습니다.