행동-가치 함수
행동-가치 함수(qπ(s,a))는 상태 s에서 a라는 행동을 취했을 때 얻을 수 있는 리턴의 기댓값을 의미합니다. 행동-가치 함수에 대한 수식은 다음과 같습니다.
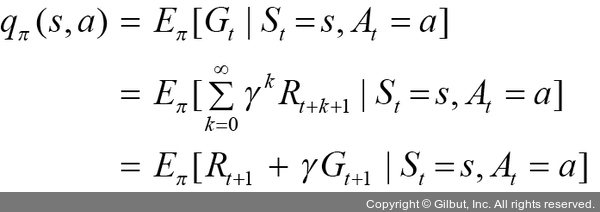
가치 함수(상태-가치 함수, 행동-가치 함수)를 계산하는 방법은 O(n3)(세제곱 시간) 시간 복잡도가 필요하기 때문에 상태 수가 많으면 적용하기가 어려운데, 이 문제를 해결하는 방법은 다음 네 가지입니다. 각 방법론은 이전 단계의 단점을 보완하고 학습 효율을 높이는 방향으로 발전되었습니다.
1. 다이나믹 프로그래밍(dynamic programming): 마르코프 결정 과정의 상태와 행동이 많지 않고 모든 상태와 전이 확률을 알고 있다면 다이나믹 프로그래밍 방식으로 각 상태의 가치와 최적의 행동을 찾을 수 있습니다. 하지만 대부분의 강화 학습 문제는 상태도 많고, 상태가 전이되는 경우의 수도 많으므로 다이나믹 프로그래밍을 적용하기 어렵습니다.
2. 몬테카를로(Monte Carlo method): 마르코프 결정 과정에서 상태가 많거나 모든 상태를 알 수 없는 경우에는 다이나믹 프로그래밍을 적용할 수 없었습니다. 몬테카를로는 전체 상태 중 일부 구간만 방문하여 근사적으로 가치를 추정합니다. 초기 상태에서 시작하여 중간 상태들을 경유해서 최종(terminal) 상태까지 간 후 최종 보상을 측정하고 방문했던 상태들의 가치를 업데이트합니다.