최적의 행동-가치 함수(optimal action-value function)
최적의 상태-가치 함수와 유사하게 최적의 행동-가치 함수(q*(s,a))는 주어진 모든 정책에 대해 행동-가치 함수의 최댓값이며, 다음 수식을 사용합니다.

행동-가치 함수는 현재 상태 s에서 정책 π를 따라 행동 a를 했을 때의 가치를 의미합니다.
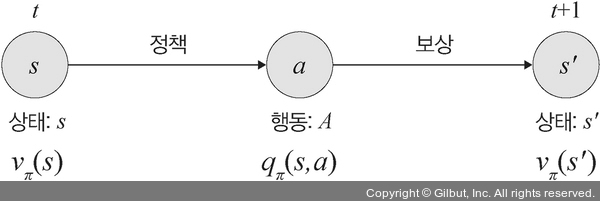
▲ 그림 12-11 행동-가치 함수
이때 행동-가치 함수(큐-함수라고도 함)에 대한 최적의 가치 함수를 구할 수 있다면 주어진 상태에서 q 값이 가장 높은 행동을 선택할 수 있게 됩니다. 따라서 최적화된 정책을 구할 수 있습니다. 이렇게 선택된 최적화된 정책은 다음 수식으로 정리할 수 있습니다.

즉, 행동-가치 함수를 최대로 하는 행동만 취하겠다는 의미입니다. 이렇듯 q*(s,a)를 찾게 되면 최적화된 정책을 구할 수 있습니다.