활용과 탐험을 반복하는 큐-러닝의 학습 절차는 다음과 같습니다.
1. 초기화: 큐-테이블(Q-table)1에 있는 모든 큐 값을 ‘0’으로 초기화합니다.
▼ 표 12-1 큐-러닝의 큐-테이블
|
큐-테이블 |
행동 |
|||||
|
Action1 |
Action2 |
… |
Actionn-1 |
Actionn |
||
|
상태 |
State1 |
0 |
0 |
… |
0 |
0 |
|
State2 |
0 |
0 |
… |
0 |
0 |
|
|
… |
… |
… |
… |
… |
… |
|
|
Staten-1 |
0 |
0 |
… |
0 |
0 |
|
|
Staten |
0 |
0 |
… |
0 |
0 |
|
예를 들어 ‘0’으로 초기화하는 코드는 다음과 같습니다.
Q = np.zeros([env.observation_space.n, env.action_space.n])
2. 행동 a를 선택하고 실행합니다.
3. 보상 r과 다음 상태 s'를 관찰합니다.
4. 상태 s'에서 가능한 모든 행동에 대해 가장 높은 큐 값을 갖는 행동인 a'를 선택합니다.
5. 다음 공식을 이용하여 상태에 대한 큐 값을 업데이트합니다.
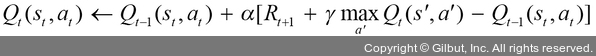
여기에서 Rt+1은 현재 상태 s에서 어떤 행동 a를 취했을 때 얻는 즉각적 보상이고, 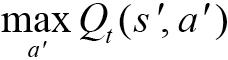 는 미래에 보상이 가장 클 행동을 했다고 가정하고 얻은 다음 단계의 가치입니다. 따라서 목표 값(target value)은
는 미래에 보상이 가장 클 행동을 했다고 가정하고 얻은 다음 단계의 가치입니다. 따라서 목표 값(target value)은 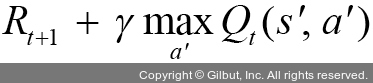 이고, 이 목표 값과 실제로 관측해서 얻은 Qt-1(st,at) 값의 차이만큼 업데이트를 진행합니다.
이고, 이 목표 값과 실제로 관측해서 얻은 Qt-1(st,at) 값의 차이만큼 업데이트를 진행합니다.
6. 종료 상태에 도달할 때까지 2~5를 반복합니다.
하지만 이러한 큐-러닝은 실제로 실행해 보면 다음 이유로 잘 동작하지 않는 경우가 빈번합니다.
• 에이전트가 취할 수 있는 상태 개수가 많은 경우 큐-테이블 구축에 한계가 있습니다.
• 데이터 간 상관관계로 학습이 어렵습니다.
이와 같은 이유로 큐-러닝은 잘 동작하지 않습니다. 이러한 큐-러닝의 단점을 보완하고자 큐-러닝 기반의 DQN(Deep Q Network)이 출현했습니다.