몬테카를로 트리 탐색 알고리즘은 총 네 단계로 학습합니다.
1. 선택: 루트 R에서 시작하여 현재까지 펼쳐진 트리 중 가장 승산 있는 자식 노드 L을 선택합니다. 이때 선택은 다음 수식을 사용합니다.
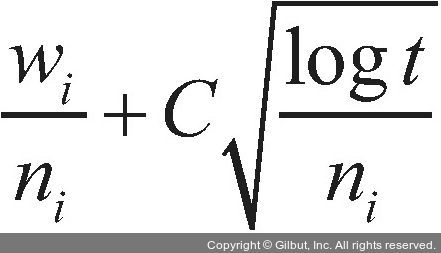
wi: i번 움직인 후의 승리 횟수입니다.
ni: i번 움직인 후의 시뮬레이션 횟수입니다.
C: 탐험 파라미터로 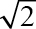 를 처음 초깃값으로 많이 사용합니다. 하지만 이 값은 실험을 해서 조정되어야 합니다.
를 처음 초깃값으로 많이 사용합니다. 하지만 이 값은 실험을 해서 조정되어야 합니다.
t: 시뮬레이션의 전체 횟수입니다. 즉, 모든 ni의 합이므로 이 값은 결국 부모 노드의 ni 값입니다.
2. 확장: 노드 L에서 게임이 종료되지 않는다면 하나 또는 그 이상의 자식 노드를 생성하고 그중 하나의 노드 C를 선택합니다.
3. 시뮬레이션: 노드 C에서 랜덤으로 자식 노드를 선택하여 게임을 반복 진행합니다.
4. 역전파: 시뮬레이션 결과로 C, L, R까지 경로에 있는 노드들의 정보를 갱신합니다.