13.2.1 오토인코더란
오토인코더는 단순히 입력을 출력으로 복사하는 신경망으로 은닉층(혹은 병목층이라고도 함)의 노드 수가 입력 값보다 적은 것이 특징입니다. 따라서 입력과 출력이 동일한 이미지라고 예상할 수 있습니다. 하지만 왜 입력을 출력으로 복사하는 방법을 사용할까요? 바로 은닉층 때문입니다. 오토인코더의 병목층은 입력과 출력의 뉴런보다 훨씬 적습니다. 즉, 적은 수의 병목층 뉴런으로 데이터를 가장 잘 표현할 수 있는 방법이 오토인코더입니다. 오토인코더는 네 가지 주요 부분으로 구성됩니다.
1. 인코더: 인지 네트워크(recognition network)라고도 하며, 특성에 대한 학습을 수행하는 부분입니다.
2. 병목층(은닉층): 모델의 뉴런 개수가 최소인 계층입니다. 이 계층에서는 차원이 가장 낮은 입력 데이터의 압축 표현이 포함됩니다.
3. 디코더: 생성 네트워크(generative network)라고도 하며, 이 부분은 병목층에서 압축된 데이터를 원래대로 재구성(reconstruction)하는 역할을 합니다. 즉, 최대한 입력에 가까운 출력을 생성하도록 합니다.
4. 손실 재구성: 오토인코더는 다음 그림과 같이 입력층과 출력층의 뉴런 개수가 동일하다는 것만 제외하면 일반적인 다층 퍼셉트론(Multi-Layer Perceptron, MLP)3과 구조가 동일합니다. 오토인코더는 압축된 입력을 출력층에서 재구성하며, 손실 함수는 입력과 출력(인코더와 디코더)의 차이를 가지고 계산합니다.
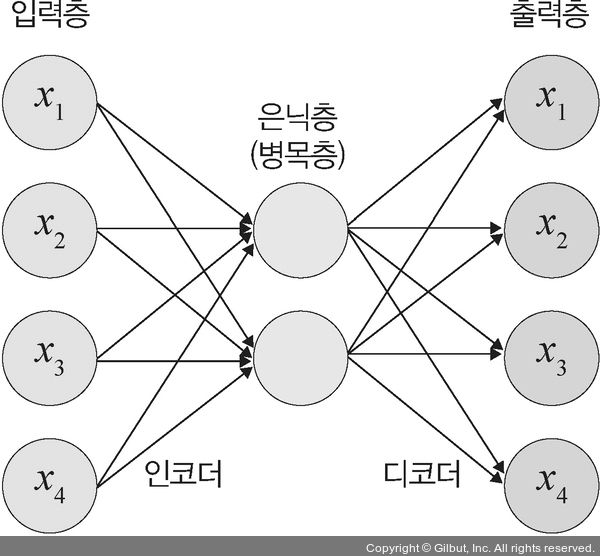
▲ 그림 13-3 오토인코더