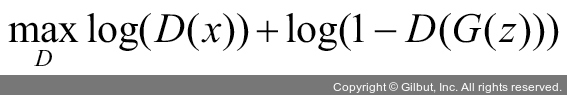GAN 구조를 살펴보았으니, 이제 GAN의 손실 함수를 살펴보겠습니다. 먼저 GAN의 손실 함수는 다음과 같습니다.

• x~Pdata(x): 실제 데이터에 대한 확률 분포에서 샘플링한 데이터
• z~Pz(z): 가우시안 분포를 사용하는 임의의 노이즈에서 샘플링한 데이터
• D(x): 판별자 D(x)가 1에 가까우면 진짜 데이터로 0에 가까우면 가짜 데이터로 판단, 0이면 가짜를 의미
• D(G(z)): 생성자 G가 생성한 이미지인 G(z)가 1에 가까우면 진짜 데이터로, 0에 가까우면 가짜 데이터로 판단
수식에서 판별자 D는 실제 이미지 x를 입력받을 경우 D(x)를 1로 예측하고, 생성자가 잠재 벡터에서 생성한 모조 이미지 G(z)를 입력받을 경우 D(G(z))를 0으로 예측합니다. 따라서 판별자가 모조 이미지 G(z)를 입력받을 경우 1로 예측하도록 하는 것이 목표입니다.
다시 앞의 손실 함수 전체로 돌아오면, 눈으로 보는 것처럼 상당히 복잡해 보입니다. 따라서 판별자 D와 생성자 G 부분으로 나누어서 살펴보겠습니다. 판별자 D는 다음 식의 최댓값으로 파라미터를 업데이트하는 것을 목표로 합니다. 참고로 판별자는 앞의 수식에서 좌항과 우항을 모두 사용합니다.