7.4 모형의 예측과 오차의 측정
머신 러닝에서의 예측은 어떻게 이루어질까? 이 질문에 앞서, 다시 데이터를 생각해보자. 데이터는 지나간 사건이나 현상에 대한 기록이라고 했다. 그 어떤 최신 데이터도 ‘과거’에 대한 기록일 뿐이다. 즉, 데이터로 보이는 값은 현재의 실시간 이벤트가 아닌, 과거의 값인 셈이다. 그렇기 때문에 데이터 기반의 모형은 모두 과거의 기록을 바탕으로 만들어진 것이며, 과거의 기록을 바탕으로 추론하고 예측한다.
하지만 과거에서 비롯된 모형이 앞으로의 일을 잘 ‘추론’하고 ‘예측’하는 것은 어려운 일이다. 모형이 실제로 미래에도 잘 작동하는지를 알려면 미래 시점의 데이터가 필요하지만, 타임 머신이 없는 한 구할 수가 없다! 결국 우리는 주어진 데이터를 활용해서 모형의 성능을 가늠해야 한다. 물론 미래의 데이터를 사용해서 진짜 성능을 파악하는 수준은 아니다 하더라도 어느 정도 모형의 성능을 가늠할 수 있을 것으로 기대할 뿐이다.
우선, 주어진 데이터를 두 덩어리로 나눈다. 하나는 모형을 수립하는 데이터셋, 다른 하나는 이렇게 수립한 모형이 얼마나 잘 작동하는지를 테스트하는 데이터셋이다.
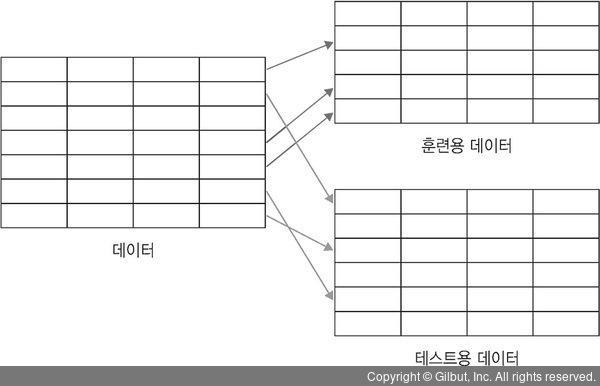
▲ 그림 7-7 데이터 파티셔닝