머신 러닝에서 머신은 컴퓨터를 의미하고, 러닝은 주어진 데이터를 분석하는 과정을 의미한다. 컴퓨터가 스스로 학습(러닝)할 수 있지만, 현재로서는 사람이 정해준 방법으로 분석한다는 점에 주목해야 한다. 즉, 사람이 데이터를 분석하는 알고리즘을 고안하고, 그 알고리즘을 다방면에 걸쳐 검토한다. 그리고 나서 알고리즘이 데이터에 적용되는 셈이다. 흥미롭게도 같은 데이터라 하더라도 어떤 목적으로, 어떤 알고리즘을 만드느냐에 따라 결과가 다르게 나올 수 있다.
대표적인 분류모형인 결정 트리(decision tree)는 1980~1990년대에 걸쳐 다양한 분야에서 많이 활용되었으며 여전히 잘 사용된다. 1990년대 중반에는 서포트 벡터 머신(Support Vector Machine, SVM)1 모형이 많이 사용되기도 하였으며, 통계학과 머신 러닝의 경계가 불분명해지며, 통계학의 오래된 모형인 로지스틱 회귀도 2001년 이후로 많이 사용되고 있다. 특히, 머신 러닝의 한 갈래인 인공 신경망은 1957년의 퍼셉트론(perception model)을 기원으로 하여 인간 두뇌의 뉴런을 모사한 모형인 신경망(neural network)으로 확장되었고 1980년대부터 많은 관심을 받기 시작했다.
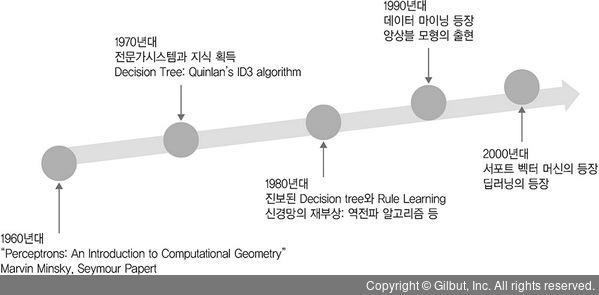
▲ 그림 8-2 머신 러닝 모형의 발달사
1 서포트 벡터 머신은 분류에 활용되는 지도 학습 머신 러닝 모형을 의미한다.