그래서 데이터의 수집과 함께, 데이터를 효과적으로 활용하기 위해 수집된 데이터에 대한 체계적인 관리(예를 들어 변수의 값은 일관성 있게 들어가 있는지, 변수명은 적절하게 부여되었는지, 각 변수에 대한 설명으로 변수의 성격을 이해할 수 있는지 등)가 중요해지고 있다. 머신 러닝과 같은 데이터 분석 기법을 이해하는 것과 함께 그 재료인 데이터의 생성부터 관리, 유통, 분석, 활용에 이르는 데이터 큐레이션에 대한 관심이 커지고 있다. 이러한 현상은 딥러닝으로 흔히 얘기되는 데이터 기반의 AI에서 더 잘 나타나고 있다. 딥러닝은 이미 알려져 있는 알고리즘이지만, 딥러닝을 어느 데이터에 적용하는지에 따라 활용 정도는 달라진다. 블랙 박스에 어떤 데이터를 넣어 결과를 활용하는지가 중요해지는 셈이다.
이러한 머신 러닝은 크게 두 가지 유형으로 나눌 수 있다. 앞서 우리가 변수 Y로 지칭했던 종속 변수를 중심으로 보면 머신 러닝의 문제는 크게 Y를 예측하거나 그렇지 않은 것으로 나누어 볼 수 있다. 전자는 지도 학습, 후자는 비지도 학습이다. 지도 학습의 경우에는 Y를 수치로 예측하거나(회귀) 그 범주를 예측하는(분류) 기법 등이 있는데, 앞서 살펴본 선형 회귀 분석이나 로지스틱 회귀 분석이 대표적인 예이다. 반면에 Y를 고려하지 않는 분석은 데이터로부터 패턴이나 군집 등을 발견하는 방식의 기법 등을 의미한다. 다음 그림 8-4는 머신 러닝의 대표적인 지도 학습과 비지도 학습의 구성을 보여준다.
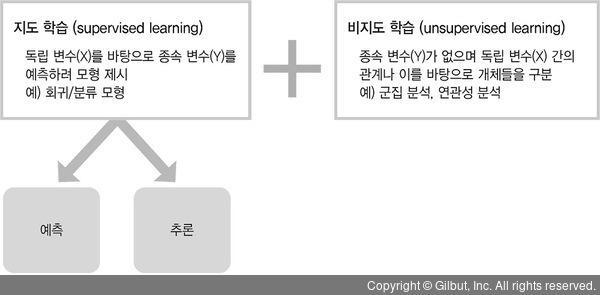
▲ 그림 8-4 지도 학습과 비지도 학습