이 대회에서는 각 모형이 100만장 이상의 이미지를 분류하는데, 2012년 AlexNet3이 오류율 16%를 기록하였고, 2014년 GoogleNet4은 오류율 7%를 기록하였다. 2015년에는 ResNet5이 152층 심층 신경망을 통해 오류율 3.6%를 기록하였으며 계속해서 오류율은 낮아지고 있는 상황이다.
최근 개방형 환경에서 머신 러닝과 딥러닝의 알고리즘이 공개되고 오픈 소스로 제공되며, 그 과정에서 기술은 지속적으로 발전한다. 그렇다면 이러한 머신 러닝과 딥러닝의 대상이 되는 데이터를 생각해보자. 우리가 다루는 데이터는 크게 정형, 반정형, 비정형 데이터로 나누었다. 재미있게도 머신 러닝과 딥러닝의 근원적 경쟁력을 확보하는 지름길은 바로, 머신 러닝, 딥러닝에 대한 이해를 바탕으로 다양한 종류의 데이터를 체계적으로 수집하고 관리하는 것이다. 비정형 데이터, 정형 데이터 모두 분석할 수 있도록 전처리를 하여 적절한 머신 러닝과 딥러닝 모형을 구현한 오픈 소스를 활용한다면 빠르게 결과를 기대할 수 있다.
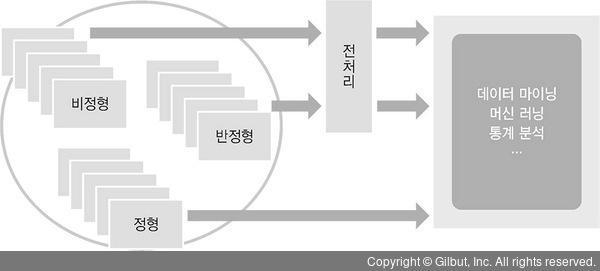
▲ 그림 8-7 다양한 데이터의 분석
최근 많이 얘기되고 있는 빅데이터의 경우도 크게 다르지 않다. 빅데이터라 하더라도 앞서 얘기한 정형/반정형/비정형 데이터로 구분할 수 있으며, 다만 그 크기가 큰 것뿐이다. 빅데이터에 대한 명확한 학술적 정의는 부족하지만, 일반적인 계산 환경에서 처리가 어려운 경우 또는 기존에는 주로 활용되지 못하였지만 이제 활용되기 시작하며 새로운 인사이트를 제공하는 데이터를 우리는 빅데이터라고 부른다. 빅데이터의 분석 역시 머신 러닝이나 딥러닝을 적용하거나 또는 회귀 분석을 하는 것은 변함이 없다. 다만, 일반적인 계산 환경에서 처리와 분석이 어려우니 이를 가능하게 하는 계산 방식과 플랫폼이 필요한 것이다. 그래서 빅데이터의 경우에는 분산/병렬 처리 또는 클라우드 컴류팅을 통해 대용량 데이터를 처리하고 분석한다.
3 합성곱 신경망의 이름으로 알렉스 크리체브스키(Alex Krizhevsky)가 고안하였다.
4 2014년 대회에서 우승한 합성곱 신경망의 이름이며, 구글의 Inception 모형의 여러 버전 중 하나이다.
5 마이크로소프트에서 만든 심층 신경망으로 2015년 대회에서 우승하였다.