만약 데이터가 크다면 어떻게 처리하고 분석할 수 있을까. 가장 효과적인 방법 중 하나는 이렇게 큰 데이터를 분석할 수 있는 컴퓨터를 마련하는 것이다. 고가의 장비를 통해서 계산하는 방법이 있다. 하지만 비용을 감당할 수 없을 정도로 큰 데이터의 경우에는 처리와 분석이 단순하게 이뤄지지는 않을 것이다. 그래서 분산 파일 시스템을 통한 데이터의 처리와 분석을 수행하는데, 이를 맵리듀스 프레임워크(mapreduce framework)라 한다. 즉, 그림 8-8과 같이 큰 데이터를 나누어 관리하고, 계산할 로직을 각 나눠진 데이터에 적용한 후 결과를 하나로 정리하는 방식이다.
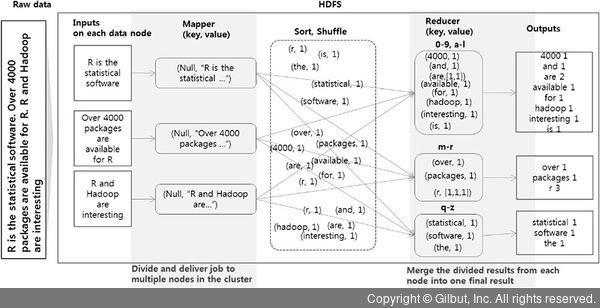
▲ 그림 8-8 빅데이터 분석을 위한 맵리듀스 프레임워크의 예
최근에는 클라우드 컴퓨팅의 확산으로 이러한 분산 파일 시스템과 함께 클라우드 환경에서 고사양의 컴퓨팅 환경을 구축해 계산하는 것을 고려할 수도 있다. 어느 경우이든 이렇게 처리되는 데이터에 대해 머신 러닝이나 딥러닝이 적용된다는 사실에는 변함이 없다. 다만, 알고리즘을 분산 파일 시스템의 맵리듀스 프레임워크에 맞게 고쳐야 한다. 결국 계산 환경은 어떻게든 마련이 될 것이고, 우리에게는 데이터에 대한 머신 러닝과 딥러닝의 활용이 과제로 남게 된다.