남성 데이터는 왼쪽에, 여성 데이터는 오른쪽에 있으므로, 앞에서 3번째(0부터 시작한다고 가정)에 있는 데이터는 남성 0세 인구수이고, 뒤에서 첫 번째 데이터(인덱스 -1)는 여성의 100세 이상 인구수입니다.
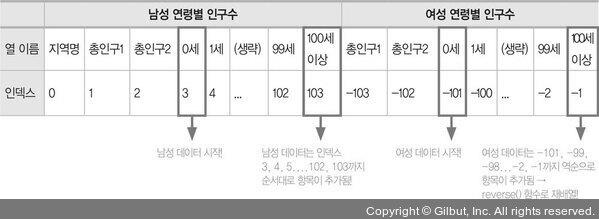
표 8-2 남성 데이터에 이어서 여성 데이터가 나옴
남성 데이터는 맨 앞에서부터 리스트 m에 차례대로 저장하면 됩니다. 여성 데이터는 인덱스 값이 -1인 100세 이상 인구수부터, 즉 맨 뒤에서부터 -1, -2, -3... 순으로 리스트 f에 저장한 후, 저장된 여성 데이터를 다시 역순으로 뒤집으면 됩니다.
이때 남성 데이터는 인덱스가 3에서 시작하고, 여성 데이터는 인덱스가 –1에서 시작된다는 점을 주의해야 합니다.
이 패턴을 코드로 표현하면 다음과 같습니다.
import csv f = open('gender.csv') data = csv.reader(f) m = [] f = [] for row in data : if '신도림' in row[0] : for i in range(0,101) : m.append(int(row[i+3])) f.append(int(row[-(i+1)])) f.reverse()
TIP
reverse( ) 함수는 리스트의 값을 역순으로 재배열하는 함수입니다.