이 결과를 보고 어떤 생각이 들었나요? 우리가 찾는 것은 인구 구조가 가장 비슷한 지역이었습니다. 즉, 연령대별 인구 비율과 분포가 가장 비슷한 지역을 찾는 것이지요. 즉, 두 지역의 차이를 합한 값이 0에 가까울수록 인구 구조가 비슷하겠지요. 그런데 지금 알고리즘에서는 음수(-) 값이 선택되어 이런 이상한 결과가 나온 것입니다.
if s < mn :
문제의 원인을 발견했으니 해결하는 것은 그렇게 어렵지 않습니다. 어떻게 해결하면 좋을까요? 절댓값을 씌워도 좋고 제곱 값을 이용할 수도 있겠네요. 여기에서는 거듭제곱 연산자를 활용해서 코드를 아주 간단하게 수정해 보겠습니다.
s = np.sum((home-away)**2)
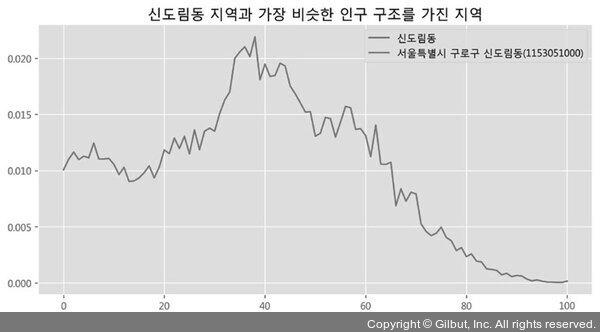
그림 14-11 음수를 제거한 결과: 신도림동이 중복 출력됨