6.2.1 R-CNN
예전의 객체 인식 알고리즘들은 슬라이딩 윈도우(sliding window) 방식4, 즉 일정한 크기를 가지는 윈도우(window)를 가지고 이미지의 모든 영역을 탐색하면서 객체를 검출해 내는 방식이었습니다. 하지만 알고리즘의 비효율성 때문에 많이 사용하지 않았으며, 현재는 선택적 탐색(selective search) 알고리즘을 적용한 후보 영역(region proposal)5을 많이 사용합니다.
R-CNN(Region-based CNN)은 이미지 분류를 수행하는 CNN과 이미지에서 객체가 있을 만한 영역을 제안해 주는 후보 영역 알고리즘을 결합한 알고리즘입니다. R-CNN의 수행 과정은 다음 그림과 같습니다.
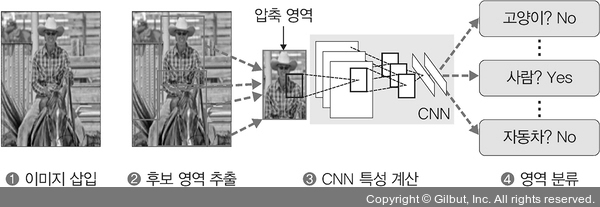
▲ 그림 6-36 R-CNN 학습 절차
1. 이미지를 입력으로 받습니다.
2. 2000개의 바운딩 박스(bounding box)를 선택적 탐색 알고리즘으로 추출한 후 잘라 내고(cropping), CNN 모델에 넣기 위해 같은 크기(227×227 픽셀)로 통일합니다(warping).
3. 크기가 동일한 이미지 2000개에 각각 CNN 모델을 적용합니다.
4. 각각 분류를 진행하여 결과를 도출합니다.