그림 1-8에서 미지수 다섯 개의 사후확률분포를 볼 수 있다. 모델에서 변환점이 42일에서 45일까지 발견되고 있음을 알 수 있다. 여러분의 생각은 어떠한가? 이 모델이 우리의 데이터를 과다적합(overfit)하였는가?
실제로 우리는 데이터에 얼마나 많은 변환점이 있을지 각자 나름대로 추측하고 있을 것이다. 예를 들어 나는 한 개의 변환점이 두 개의 변환점보다 더 가능성이 크고, 두 개의 변환점이 세 개의 변환점보다 더 가능성이 크다고 생각한다. 이것은 우리가 많은 변환점이 존재할 수 있는 사전확률분포를 만들어야 하고, 모델을 결정할 수 있어야 한다는 점을 시사한다. 우리의 모델을 훈련시킨 다음, 변환점 하나가 가장 가능성이 크다고 결정할 수 있다. 이런 일을 하는 코드는 이 장의 범위를 벗어나는 것이다. 나는 그저 데이터를 검토하는 회의적인 태도를 통해 우리의 모델을 바라보는 아이디어를 소개하고 싶었다.
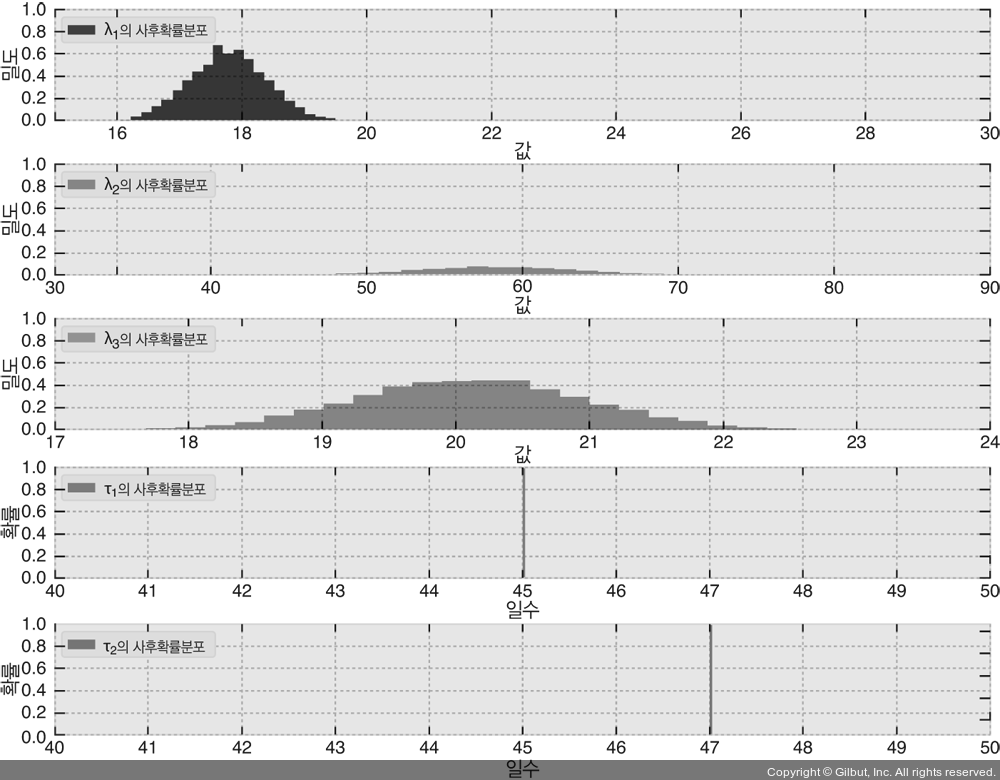
▲ 그림 1-8 확장된 문자 메시지 모델에서 미지의 모수 다섯 개에 대한 사후확률분포