미지수 pA에 대한 사후확률분포를 그림 2-5에 나타내었다.
figsize(12.5, 4) plt.title("$p_A$의 사후확률분포, A 사이트의 진짜 효율성") plt.vlines(p_true, 0, 90, linestyle="--", label="진짜 $p_A$ (미지수)") plt.hist(mcmc.trace("p")[:], bins=25, histtype="stepfilled", normed=True) plt.xlabel("$p_A$ 값") plt.ylabel("밀도") plt.legend();
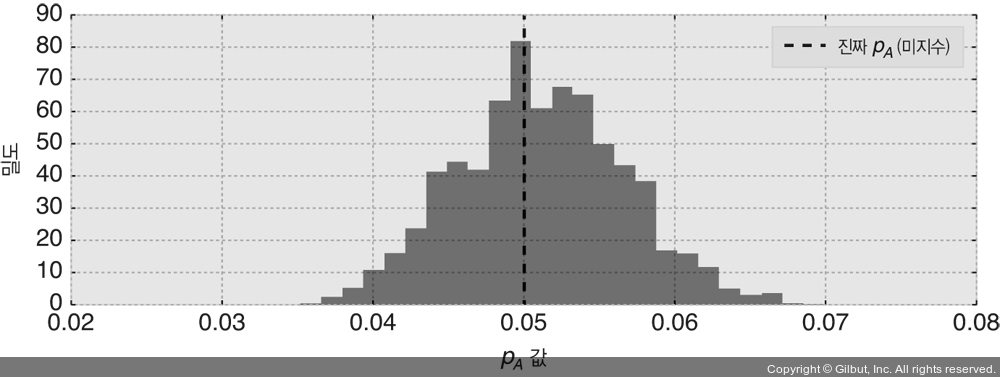
▲ 그림 2-5 pA의 사후확률분포, A 사이트의 진짜 효율성
우리의 사후확률분포는 데이터가 제시하는 진짜 pA 값 주변에 가중치를 둔다. 분포의 키가 클수록 가능성이 더 커진다. 관측치 N의 수를 변경하고 사후확률분포가 어떻게 변하는지 관측해보라.
(왜 y축이 1보다 클까? 정답은 참고자료 2의 웹페이지를 보기 바란다).