(2) 유사 데이터를 분류하는 데 사용
단어 의미가 유사한 것으로 클러스터링(clustering)되도록 합니다.
클러스터링
데이터들의 특성을 파악하여 특성이 유사한 데이터끼리 집단(군집)을 정의 하는 것입니다
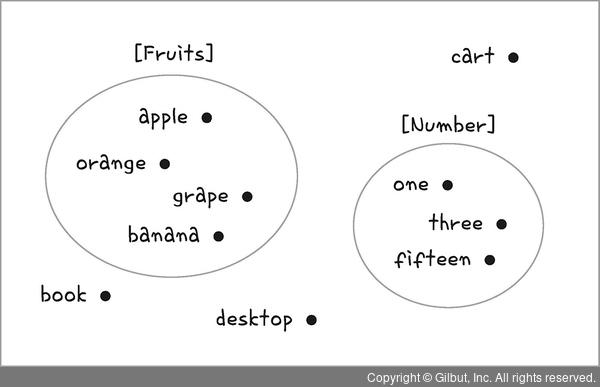
그림 10-18 | 단어 의미에 따른 클러스터링
그림 10-18과 같이 데이터가 총 열 개로 구성되어 있을 때, 단어 의미가 유사한 단어끼리 분류하여 벡터화(vecterized)할 수 있습니다. {apple, orange, grape, banana}는 과일(Fruits)로 클러스터링이 가능하므로 숫자 ‘1’로 설정하여 벡터화하고, {one, three, fifteen}은 숫자(Number)로 클러스터링이 가능하므로 숫자 ‘2’로 설정하여 벡터화합니다. 즉, 무작위 숫자를 부여하는 것이 아니라 의미를 고려하여 숫자를 적용하고 이를 벡터로 변환합니다.
인공지능을 하려면 데이터에 어떤 특징이 있는지 찾아 벡터로 만들어야 합니다. 즉, 데이터를 벡터로 만드는 것이 인공지능의 시작이라고 할 수 있습니다.