머신 러닝의 주요 구성 요소는 데이터와 모델(모형)입니다.
데이터는 머신 러닝이 학습 모델을 만드는 데 사용하는 것으로, 훈련 데이터가 나쁘다면 실제 현상의 특성을 제대로 반영할 수 없으므로 실제 데이터의 특징이 잘 반영되고 편향되지 않는 훈련 데이터를 확보하는 것이 중요합니다.
또한, 학습에 필요한 데이터가 수집되었다면 훈련을 위해 ‘훈련 데이터셋’과 ‘검증 데이터셋’ 용도로 분리해서 사용합니다. 보통 데이터의 80%는 훈련용으로, 20%는 검증용으로 분리해서 사용합니다.
모델은 머신 러닝의 학습 단계에서 얻은 최종 결과물로 가설이라고도 합니다. 예를 들어 “입력 데이터의 패턴은 A와 같다.”라는 가정을 머신 러닝에서는 모델이라고 합니다. 모델의 학습 절차는 다음과 같습니다.
1. 모델(또는 가설) 선택
2. 모델 학습 및 평가
3. 평가를 바탕으로 모델 업데이트
이 세 단계를 반복하면서 주어진 문제를 가장 잘 풀 수 있는 모델을 찾습니다.
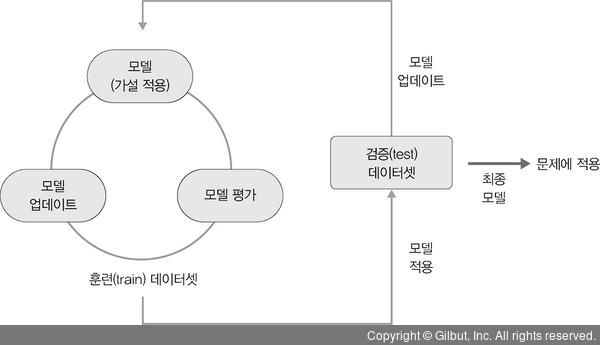
▲ 그림 1-5 머신 러닝의 문제 풀이 과정
최종적으로 완성된 모델(모형)을 해결하고자 하는 문제에 적용해서 분류 및 예측에 대한 결과를 도출합니다.