10.2.3 엘모
엘모(ELMo, Embeddings from Language Model)는 2018년에 제안된 임베딩 모델입니다. 엘모의 가장 큰 특징은 사전 훈련된 언어 모델(pre-trained language model)을 사용하는 것으로, 엘모 이름에 LM(Language Model)이 들어간 이유이기도 합니다.
현재까지 임베딩 한계를 극복하고자 많은 모델에 대한 논문들이 발표되고 있는데, 그중 하나의 방법으로 주어진 문장의 문맥을 고려한 임베딩 방법이 엘모입니다. 엘모는 기존 모델처럼 각 단어에 고정된 임베딩을 사용하는 대신, 전체 문장을 고려하여 각 단어에 임베딩을 합니다. 엘모는 특정 데이터로 사전 훈련된 양방향 LSTM 모델을 이용합니다. 순방향 LSTM은 주어진 문장에서 시작부터 n개의 단어를 이용하여 n+1번째 단어를 예측합니다. 역방향 LSTM은 주어진 문장의 n에서 역순으로 n-1번째 단어를 예측합니다.
언어를 학습할 때는 양방향 LSTM이 생성한 은닉 상태를 이어 붙인 벡터를 토대로 소프트맥스 함수를 사용하여 다음 단어를 예측합니다. 간단히 정리하면 기존 단어 임베딩, 순방향 LSTM, 역방향 LSTM을 모두 종합하여 이어 붙인 벡터가 엘모의 임베딩입니다.
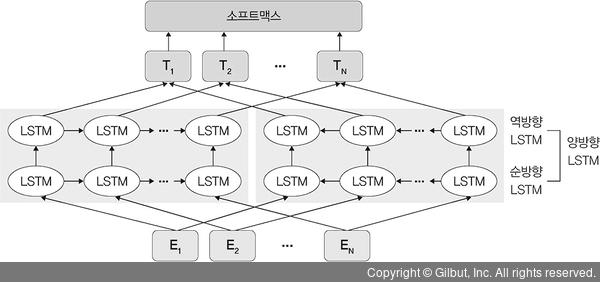
▲ 그림 10-15 엘모의 순방향과 역방향