• 모델(모형) 정의: 모델(모형) 정의 단계에서 신경망을 생성합니다. 일반적으로 은닉층 개수가 많을수록 성능이 좋아지지만 과적합3이 발생할 확률이 높습니다. 즉, 은닉층 개수에 따른 성능과 과적합은 서로 상충 관계에 있다고 할 수 있습니다. 따라서 모델 정의 단계에서 신경망을 제대로 생성하는 것이 중요합니다.
• 모델(모형) 컴파일: 컴파일 단계에서 활성화 함수4, 손실 함수5, 옵티마이저6를 선택합니다. 이때 데이터 형태에 따라 다양한 옵션이 가능합니다. 훈련 데이터셋 형태가 연속형7이라면 평균 제곱 오차(Mean Squared Error, MSE)를 사용할 수 있으며, 이진 분류(binary classification)8라면 크로스 엔트로피(cross-entropy)를 선택합니다. 또한, 과적합을 피할 수 있는 활성화 함수 및 옵티마이저 선택이 중요합니다.
• 모델(모형) 훈련: 훈련 단계에서는 한 번에 처리할 데이터양을 지정합니다. 이때 한 번에 처리해야 할 데이터양이 많아지면 학습 속도가 느려지고 메모리 부족 문제를 야기할 수 있기 때문에 적당한 데이터양을 선택하는 것이 중요합니다. 따라서 전체 훈련 데이터셋에서 일정한 묶음으로 나누어 처리할 수 있는 배치와 훈련의 횟수인 에포크 선택이 중요합니다. 이때 훈련 과정에서 값의 변화를 시각적으로 표현하여 눈으로 확인하면서 파라미터9와 하이퍼파라미터10에 대한 최적의 값을 찾을 수 있어야 합니다.
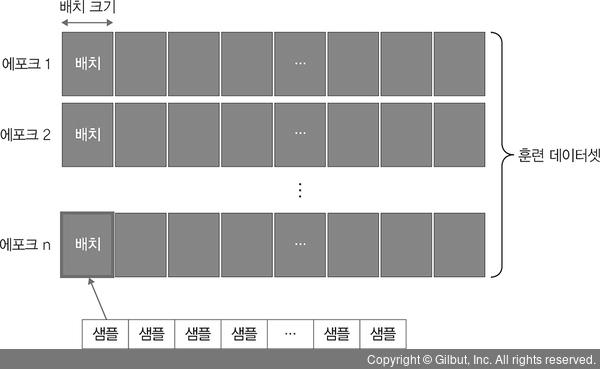
▲ 그림 1-11 모델 훈련에 필요한 하이퍼파라미터
3 훈련 데이터를 과하게 학습하여 훈련 데이터에서는 오차가 감소하지만, 새로운 데이터에서는 오차가 커지는 것을 의미합니다.
4 활성화 함수는 입력 신호가 일정 기준 이상이면 출력 신호로 변환하는 함수로 시그모이드, 하이퍼볼릭 탄젠트, 렐루 등이 있습니다. ‘4장 딥러닝 시작’에서 자세히 다룹니다.
5 손실 함수는 모델의 출력 값과 사용자가 원하는 출력 값(레이블)의 차이, 즉 오차를 구하는 함수로 평균 제곱 오차(mean squared error)와 크로스 엔트로피 오차(cross entropy error)가 있습니다. ‘4장 딥러닝 시작’에서 자세히 다룹니다.
6 옵티마이저는 손실 함수를 기반으로 네트워크 업데이트 방법을 결정합니다. 업데이트 결정 방법에 사용되는 것으로는 아담(Adam), 알엠에스프롭(RMSProp) 등이 있습니다. ‘4장 딥러닝 시작’에서 자세히 다룹니다.
7 연속적인 값을 갖는 데이터입니다.
8 ‘그렇다/아니다’처럼 두 개로 분류하는 것입니다.
9 모델 내부에서 결정되는 변수입니다.
10 튜닝 또는 최적화해야 하는 변수로, 사람들이 선험적 지식으로 설정해야 하는 변수입니다.