군집은 아무런 정보가 없는 상태에서 데이터를 분류하는 방법입니다. 한 클러스터 안의 데이터는 매우 비슷하게 구성하고, 다른 클러스터의 데이터와 구분되도록 나누는 것이 목표입니다. 군집은 머신 러닝의 군집과 다르지 않습니다. 하지만 머신 러닝에서 군집화를 처리할 때 딥러닝과 함께 사용하면 모델 성능을 높일 수 있기 때문에 머신 러닝 단독으로 군집 알고리즘을 적용하기보다 딥러닝과 함께 쓰면 좋습니다(신경망에서 군집 알고리즘 사용).
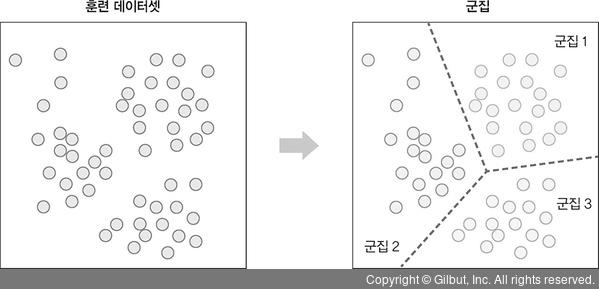
▲ 그림 1-17 군집
전이 학습(transfer learning)은 사전에 학습이 완료된 모델(pre-training model)(사전 학습 모델)을 가지고 우리가 원하는 학습에 미세 조정 기법을 이용하여 학습시키는 방법입니다. 따라서 전이 학습에는 사전에 학습이 완료된 모델이 필요하며, 학습이 완료된 모델을 어떻게 활용하는지에 대한 접근 방법이 필요합니다.
사전 학습 모델은 풀고자 하는 문제와 비슷하면서 많은 데이터로 이미 학습이 되어 있는 모델입니다. 일반적으로 많은 데이터를 구하기도 어렵지만, 많은 데이터로 모델을 학습시키는 것은 오랜 시간과 연산량이 필요합니다. VGG, 인셉션(Inception), MobileNet 같은 사전 학습 모델을 사용하면 효율적인 학습이 가능합니다. 따라서 분석하려는 주제에 맞는 사전 학습 모델을 선택하고 활용합니다. 사전 학습 모델을 활용하는 방법으로 특성 추출과 미세 조정 기법이 있는데, ‘5장 합성곱 신경망 I’에서 자세히 다룹니다.
강화 학습은 머신 러닝과 동일하기 때문에 설명을 생략합니다.