마지막으로 정확도와 손실에 대한 정보를 수치상 표현하고자 한다면 다음 코드를 이용합니다.
코드 8-9 정확도와 손실 정보 표현
loss_and_metrics = model1.evaluate(X_test, y_test)
print('## 손실과 정확도 평가 ##')
print(loss_and_metrics)
다음은 정확도와 손실 정보를 표현한 결과입니다.
1/1 [==============================] - 0s 1ms/step - loss: 0.5317 - accuracy: 0.9333
## 손실과 정확도 평가 ##
[0.5316773653030396, 0.9333333373069763]
결과 그래프가 뭔가 이상합니다. 일반적으로 검증 데이터에 대한 손실 값(val loss)은 시간이 흐를수록 감소해야 하지만, 앞의 그래프는 시간이 흐를수록 계속 증가합니다. 반면 훈련 정확도(train accuracy)는 100%에 가깝고, 훈련 손실 값(train loss)은 0에 가까운 값을 유지하고 있습니다. 즉, 훈련 데이터셋에 대한 정확도는 높으나 검증 데이터셋에 대한 정확도는 낮습니다. 이것에 대한 원인은 다양하지만, 해결 방법도 다양합니다. 여기에서는 배치 정규화를 적용하여 문제를 해결해 보겠습니다.
학습이 진행될 때마다 은닉층에서는 입력 분포가 변화하면서 가중치가 엉뚱한 방향으로 갱신되는 문제가 종종 발생합니다. 즉, 신경망의 층이 깊어질수록 학습할 때 가정했던 입력 분포가 변화하여 엉뚱한 학습이 진행될 수 있는데, 배치 정규화를 적용해서 입력 분포를 고르게 맞추어 주면서 과적합을 해결해 보겠습니다.
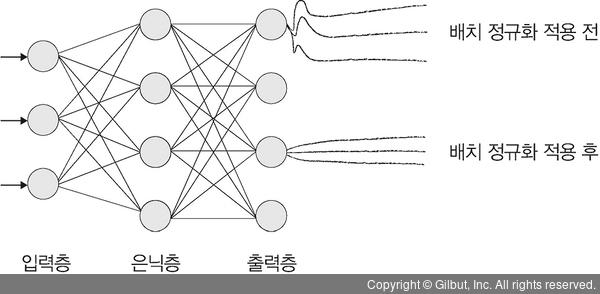
▲ 그림 8-37 배치 정규화