즉, 가치 함수는 현재 시점에서 미래의 모든 기대되는 보상을 표현하는 미래 가치라고 할 수 있습니다. 따라서 강화 학습의 핵심은 가치 함수를 최대한 정확하게 찾는 것입니다. 다시 말해 미래 가치가 가장 클 것으로 기대되는 결정을 하고 행동하는 것이 강화 학습의 목표라고 할 수 있습니다.
그러면 병원을 방문한 어느 하루에 대한 마르코프 프로세스에 보상을 추가해 보겠습니다. 예를 들어 대기에서 독서로 이동할 때의 보상이 추가되었는데, 이때의 보상이 +10이 됩니다.
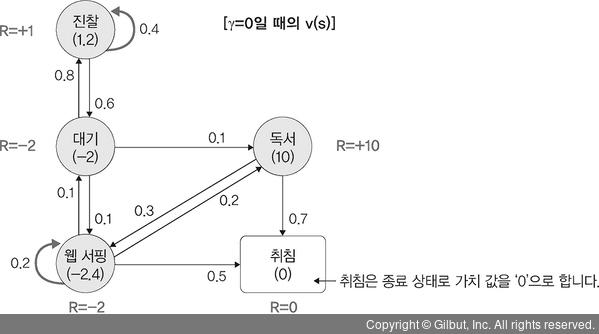
▲ 그림 12-6 마르코프 프로세스 사례에 할인율 0 반영
예제에서 γ=0일 때 ‘웹 서핑’에 대한 가치(value) 값을 -2.4로, ‘진찰’에 대한 가치 값을 1.2로 가정하면 ‘독서’와 ‘대기’에 대한 가치는 다음과 같이 구할 수 있습니다.
“독서” = 10 + 0×[(-2.4×0.3) + (0×0.7)] = 10
“대기” = -2 + 0×[(-2.4×0.1) + (10×0.1) + (1.2×0.8)] = -2