정책 발전
정책 발전(policy improvement)으로 가장 많이 알려진 방법이 욕심쟁이 정책 발전(greedy policy improvement)입니다. 욕심쟁이 정책 발전은 에이전트가 할 수 있는 행동들의 행동-가치 함수를 비교하고 가장 큰 함수 값을 가진 행동을 취하는 것입니다. 따라서 욕심쟁이 정책 발전으로 정책을 업데이트하면 이전 가치 함수에 비해 업데이트된 정책으로 움직였을 때 받을 가치 함수는 무조건 크거나 같고, 장기적으로 최적화된 정책에 수렴할 수 있습니다. 정책 발전에서 사용되는 수식은 다음과 같습니다.
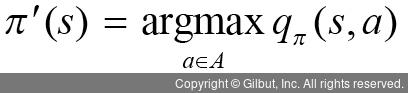
가치 이터레이션
가치 이터레이션(value iteration)은 최적의 정책을 가정하고 벨만 최적 방정식을 이용하여 순차적으로 행동을 결정합니다. 가치 이터레이션은 정책 이터레이션과 달리 따로 정책 발전이 필요하지 않습니다. 벨만 최적 방정식으로 문제를 푸는 이 방법은 한 번의 정책 평가 과정을 거치면 최적의 가치 함수와 최적의 정책이 구해지면서 MDP 문제를 풀 수 있기 때문입니다. 가치 이터레이션에서 사용하는 수식은 다음과 같습니다.
