12.4.1 큐-러닝
큐-러닝은 에이전트가 주어진 상태에서 행동을 취했을 경우 받을 수 있는 보상의 기댓값을 예측하는 큐-함수(Q-function)를 사용하여 최적화된 정책을 학습하는 강화 학습 기법입니다. 즉, 큐-러닝은 여러 실험(episode)을 반복하여 최적의 정책을 학습합니다.
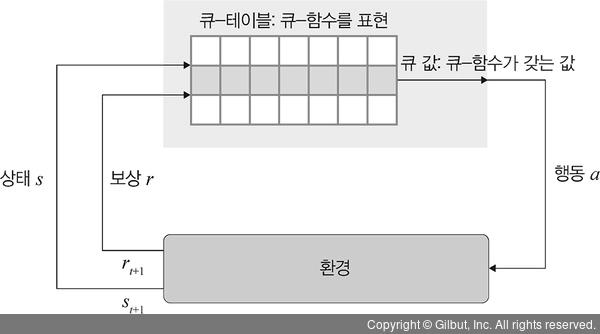
▲ 그림 12-12 큐-러닝
매 실험에서 각 상태마다 행동을 취하는데, 이때 행동은 랜덤한 선택을 하게 합니다. 그 이유는 가 보지 않을 곳을 탐험하면서 새로운 좋은 경로를 찾으려고 하기 때문이죠. 이렇듯 새로운 길을 탐험하는 것을 말 그대로 탐험이라 정의하고, 욕심쟁이(greedy) 방법을 이용하여 수행합니다. 0~1 사이로 랜덤하게 난수를 추출해서 그 값이 특정 임계치(threshold)(예 0.1)보다 낮으면 랜덤하게 행동을 취합니다. 그리고 임계치는 실험이 반복되면서(학습이 진행되면서) 점점 낮은 값을 갖습니다. 따라서 학습이 수만 번 진행되면 임계치 값은 거의 0에 수렴되고, 행동을 취하고, 보상을 받고, 다음 상태를 받아 현재 상태와 행동에 대한 큐 값을 업데이트하는 과정을 무수히 반복합니다.