리플레이 메모리
리플레이 메모리(replay memory)는 에이전트가 수집한 데이터를 저장해 두는 저장소입니다. 큐-러닝에서는 데이터들 간의 상관관계로 학습 속도가 느려지는 문제가 있었는데, 딥 큐-러닝에서는 리플레이 메모리를 도입하여 해결하고 있습니다. 즉, 에이전트 상태가 변경되어도 즉시 훈련시키지 않고 일정 수의 데이터가 수집되는 동안 기다립니다. 나중에 일정 수의 데이터가 리플레이 메모리(버퍼)에 쌓이게 되면 랜덤하게 데이터를 추출하여 미니 배치를 활용해서 학습합니다. 이때 하나의 데이터에는 상태, 행동, 보상, 다음 상태가 저장됩니다.

데이터 여러 개로 훈련을 수행한 결과들을 모두 수렴하여 결과를 내므로 상관관계 문제를 해결할 수 있습니다.
합성곱 신경망을 활용한 큐-함수
딥 큐-러닝은 큐 값의 정확도를 높이려고 합성곱 신경망을 도입했습니다.
이제 딥 큐-러닝을 예제로 살펴보겠습니다.
게임에서 택시는 랜덤한 위치에서 시작하고 승객은 랜덤한 위치(R, G, B, Y)에서 탑승합니다. 택시 기사는 승객 위치로 이동하여 승객을 태우고 목적지까지 이동합니다. 여기에서 목적지는 승객이 출발한 위치를 제외한 나머지 위치 중 하나가 됩니다. 승객이 목적지에서 내리면 게임은 끝납니다.
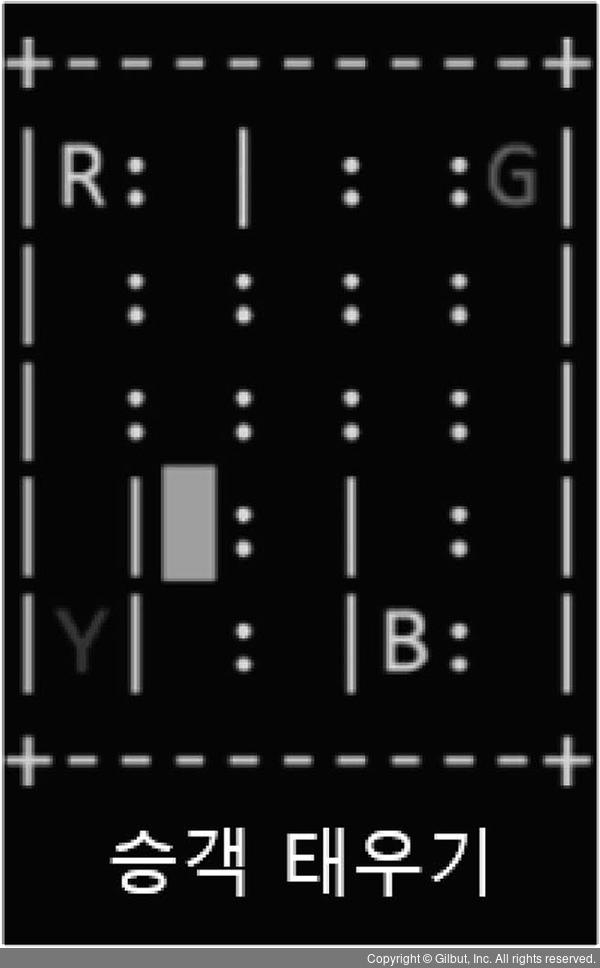
▲ 그림 12-15 딥 큐-러닝 예제