2. 확장: 노드 L에서 게임이 종료되지 않는다면 하나 또는 그 이상의 자식 노드를 생성하고 그중 하나의 노드 C를 선택합니다.
3. 시뮬레이션: 노드 C에서 랜덤으로 자식 노드를 선택하여 게임을 반복 진행합니다.
4. 역전파: 시뮬레이션 결과로 C, L, R까지 경로에 있는 노드들의 정보를 갱신합니다.
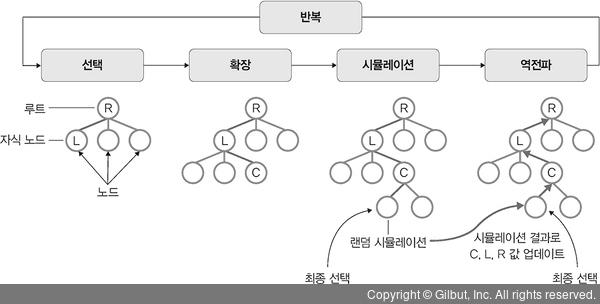
▲ 그림 12-17 몬테카를로 트리 탐색
이와 같이 몬테카를로 트리 탐색은 최선의 선택을 하기 위한 방법으로 트리에서 랜덤 시뮬레이션을 이용하여 최적의 선택을 결정합니다. 이때 임의로 시행되는 다수의 시뮬레이션으로 각각의 움직임을 측정한 후 효율적인 경우의 수를 예측합니다. 몬테카를로 트리 탐색을 이용한 대표적 알고리즘이 알파고입니다. 또한, 보드 게임, 실시간 비디오 게임, 포커 같은 비결정적 게임에도 사용됩니다.