반면 생성자 G의 역할은 판별자 D가 진짜인지 가짜인지 구별할 수 없을 만큼 진짜와 같은 모조 이미지를 노이즈 데이터를 사용하여 만들어 내는 것입니다. 예를 들어 실제 이미지인 알파벳 z가 입력으로 주어졌을 때 판별자는 z를 학습합니다. 또한, 생성자는 임의의 노이즈 데이터를 사용하여 모조 이미지 z'(G(z))를 생성합니다. 이러한 G(z)를 다시 판별자 D의 입력으로 주면 판별자는 G(z)가 실제 이미지일 확률을 반환합니다.
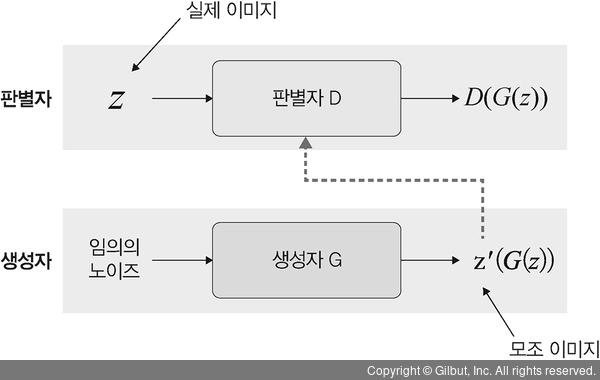
▲ 그림 13-15 생성자와 판별자
실제 데이터를 판단하려고 판별자 D를 학습시킬 때는 생성자 G를 고정시킨 채 실제 이미지(x∼pdata(x))는 높은 확률을 반환하는 방향으로, 모조 이미지(z∼pz(z))는 낮은 확률을 반환하는 방향으로 가중치를 업데이트합니다.
GAN 구조를 살펴보았으니, 이제 GAN의 손실 함수를 살펴보겠습니다. 먼저 GAN의 손실 함수는 다음과 같습니다.

• x~pdata(x): 실제 데이터에 대한 확률 분포에서 샘플링한 데이터
• z~pz(z): 가우시안 분포를 사용하는 임의의 노이즈에서 샘플링한 데이터
• D(x>): 판별자 D(x)가 1에 가까우면 진짜 데이터로, 0에 가까우면 가짜 데이터로 판단, 0이면 가짜를 의미
• D(G(z)): 생성자 G가 생성한 이미지인 G(z)가 1에 가까우면 진짜 데이터로, 0에 가까우면 가짜 데이터로 판단